Agent Economics
& Cost Governance
Per-agent cost tracking, budget enforcement, model routing, and ROI dashboards — so insurance companies always know exactly what their AI factory costs and why.
Problem Statement
AI agents consume tokens, compute, and external API calls at scale — but today there is zero visibility into what any of it costs.
Critical Gap
An agent stuck in a loop can burn through a monthly budget in minutes. Without real-time enforcement, a single runaway agent can generate thousands of dollars in unexpected API costs before anyone notices.
No Cost Visibility
Teams have no idea what each agent costs per task, per session, or per project. LLM invoices are a black box — total spend with no attribution.
No Budget Guardrails
Nothing prevents an agent from exceeding any spending threshold. There are no caps, no warnings, and no automatic pauses when costs spike.
No Model Routing
Every task uses the same model regardless of complexity. Formatting a JSON file gets billed at the same rate as a multi-file architectural review.
No ROI Justification
Insurance companies need to show value to procurement. Without cost-per-feature tracking, there's no data to justify AI development investment.
Insurance Context
Insurance companies operate under strict cost controls and fiduciary obligations. Unpredictable AI infrastructure spend is a blocker for procurement approval. Cost predictability — not just performance — is a first-class requirement for this sector.
Architecture Overview
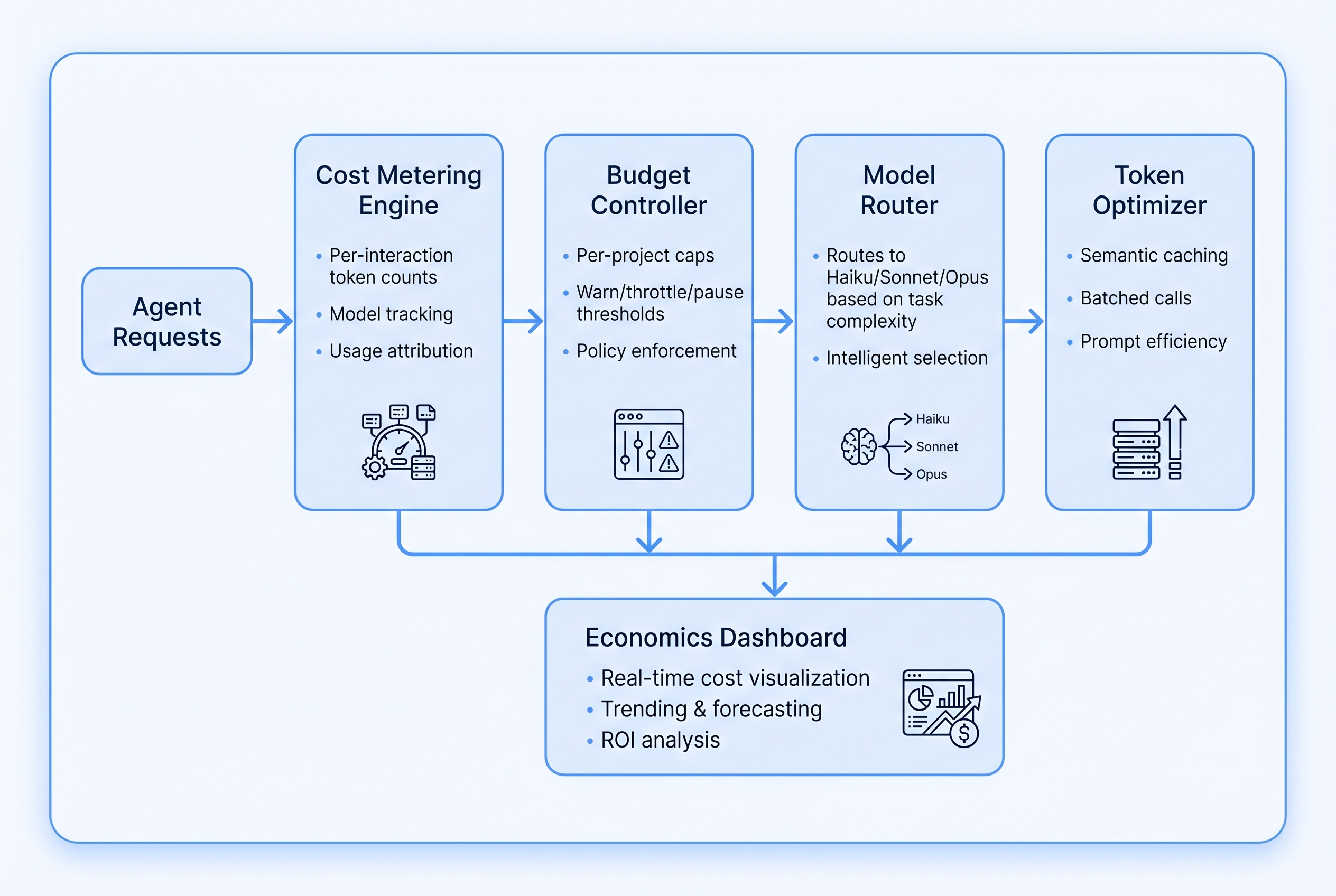
Six purpose-built components form the economics layer, sitting between the agent orchestration plane and the external LLM providers.
Cost Metering Engine
Intercepts every LLM call, tool invocation, and external API request. Records token counts (input/output/cache), model used, latency in milliseconds, and computed dollar cost per interaction. Emits structured cost events to the audit bus with sub-100ms overhead.
Budget Controller
Maintains per-project and per-agent budget caps with configurable threshold actions. Warns at 80%, throttles new task dispatch at 90%, auto-pauses at 100% with graceful task handoff — saving context and state so work can resume when the budget resets.
Model Router
Routes every task to the cheapest model capable of completing it. Uses complexity signals extracted from task metadata: token length estimate, tool call count, code diff size, and task classification labels. Haiku for boilerplate; Sonnet for standard; Opus for architecture.
Token Optimizer
Reduces token consumption through semantic caching (unchanged files are not re-read), batched tool calls (multiple reads in one round-trip), and context window management that prunes stale conversation history before it inflates costs.
Economics Dashboard
Real-time cost visualization by agent, project, and session. Displays current spend vs. budget, cost-per-feature metrics, trend charts with rolling 30-day history, and spend forecasting based on current burn rate. Built for both engineering teams and finance stakeholders.
Chargeback Engine
Allocates AI infrastructure costs to internal projects, departments, and cost centers for insurance company internal billing. Generates monthly chargeback reports with line-item detail by project and feature, suitable for finance system ingestion.
Data Flow
Agent makes LLM call → Metering Engine intercepts and records → Budget Controller checks cap → if within budget, call proceeds → response returns with cost appended → event published to audit bus → Dashboard updates in real time → Chargeback Engine accumulates for period-end reporting.
Key Components
Detailed specifications for each subsystem, including pricing models, routing rules, threshold actions, caching strategies, and cost allocation taxonomy.
3.1 — Model Tier Pricing
| Tier | Model | Input (per 1M tokens) | Output (per 1M tokens) | Cache Read | Best For |
|---|---|---|---|---|---|
| Tier 1 — Haiku | claude-haiku-3-5 | $0.80 | $4.00 | $0.08 | Formatting, linting, docstrings, boilerplate generation, simple Q&A |
| Tier 2 — Sonnet | claude-sonnet-4-5 | $3.00 | $15.00 | $0.30 | Standard implementation, bug fixes, test generation, API integration |
| Tier 3 — Opus | claude-opus-4-5 | $15.00 | $75.00 | $1.50 | Architecture design, security review, complex reasoning, cross-system planning |
3.2 — Model Routing Decision Matrix
| Task Type | Complexity Signal | Est. Token Range | Routed To | Fallback |
|---|---|---|---|---|
| Code formatting / linting | Single-file, no reasoning | <2K tokens | Haiku | — |
| Docstring / comment generation | Isolated, low context | <4K tokens | Haiku | — |
| Unit test generation | Single function, clear spec | 2K–8K tokens | Haiku | Sonnet |
| Bug fix (isolated) | Stack trace + single file | 4K–12K tokens | Sonnet | — |
| Feature implementation | Multi-file, spec provided | 8K–32K tokens | Sonnet | — |
| API integration | External schema + mapping | 8K–24K tokens | Sonnet | — |
| Security/compliance review | Multi-file, cross-cutting | 16K–64K tokens | Opus | — |
| Architecture design | System-level reasoning | 12K–48K tokens | Opus | — |
| Complex multi-system bug | Cross-repo, unknown root cause | >24K tokens | Opus | — |
3.3 — Budget Threshold Actions
| Threshold | Trigger Condition | Automated Action | Notification | Override Allowed? |
|---|---|---|---|---|
| 60% | Agent crosses 60% of session cap | None — monitoring only | Info log | N/A |
| 80% | Agent crosses 80% of cap | Downgrade routing tier by one level | Dashboard alert | Yes, by project admin |
| 90% | Agent crosses 90% of cap | Throttle: pause new task dispatch, complete active task | Slack + email | Yes, with explicit approval |
| 100% | Budget exhausted | Hard pause: save state, queue remaining tasks, halt billing | All channels + webhook | Only by billing admin |
| Anomaly | Agent exceeds 10× baseline cost/task | Immediate pause + anomaly flag on audit trail | PagerDuty / webhook | After investigation sign-off |
3.4 — Caching Strategies & Hit Rate Targets
| Cache Layer | What Is Cached | TTL | Hit Rate Target | Estimated Savings |
|---|---|---|---|---|
| Prompt Cache (native) | System prompts, static context blocks | 5 minutes (sliding) | ≥ 70% | 90% reduction on cache reads vs. full input |
| File Content Cache | Unchanged file reads (by git SHA) | Until next commit | ≥ 60% | Eliminates redundant file-read tokens |
| Semantic Result Cache | Equivalent task outputs (cosine similarity ≥ 0.95) | 24 hours | ≥ 20% | Full LLM call cost avoided |
| Tool Response Cache | External API responses (read-only endpoints) | Configurable (default 1 hour) | ≥ 40% | Avoids external API call costs + latency |
| Context Compression | Long conversation history → compressed summary | Triggered at 75% context window | N/A — always runs | 20–40% reduction in context tokens |
3.5 — Cost Allocation Taxonomy
| Dimension | Granularity | Example Values | Used For |
|---|---|---|---|
| Organization | Top level | Acme Insurance Group | Enterprise billing, contract compliance |
| Department | Business unit | Underwriting, Claims, IT | Internal chargeback, budget approval |
| Project | Initiative or product | Claims Portal v2, Policy API | Project ROI calculation, PO reconciliation |
| Feature | User story / ticket | FEAT-142: Auto-approval rules | Cost-per-feature, sprint cost tracking |
| Agent | Individual agent instance | orchestrator-7f2a, coder-3b9c | Agent efficiency analysis, anomaly detection |
| Session | Single work session | session-2026-04-02-0912 | Per-run cost audit, replay analysis |
Requirements
Fourteen formally specified requirements for the Agent Economics & Cost Governance subsystem.
Every agent instance must have an associated cost ledger that accumulates spend by LLM call, tool use, and external API call. Cost records must be queryable by agent ID with millisecond-precision timestamps.
Cost data must be aggregatable at session scope (single agent run) and project scope (all agents across all sessions for a given project). All three scopes — agent, session, project — must be independently queryable without recomputation.
Budget caps must be enforceable at the agent level and the project level. Caps are configurable per project by administrators. Enforcement must apply within one LLM call cycle — no cost overrun exceeding one call's maximum cost beyond the cap.
The Model Router must classify every task prior to dispatch and select the cheapest model tier capable of completing it. Routing decisions must be logged with the signals used. Manual tier override must be available with audit trail entry.
The Token Optimizer must maintain a semantic cache with per-cache-layer TTL configuration. Cache hits must be logged as cost savings events. Cache invalidation must be triggered by code changes (via git SHA tracking) and configurable time expiry.
The system must detect agents consuming more than 10× their rolling 7-day average cost per task and immediately pause the agent pending review. Anomaly events must be emitted to the governance audit bus with full context (agent ID, task ID, cost, baseline).
The Chargeback Engine must generate monthly cost allocation reports broken down by organization, department, project, and feature. Reports must be exportable as CSV and JSON. Report generation must complete within 60 seconds for up to 12 months of history.
For each completed feature, the system must calculate and store: AI cost incurred, estimated manual development time (configurable hours-per-story-point baseline), estimated manual cost (configurable hourly rate), and computed ROI ratio. ROI data must be surfaced in the dashboard.
The Economics Dashboard must update in real time (≤2 second lag from event emission). It must display current spend vs. budget for all active projects, per-agent cost breakdown for the current session, and a live cost rate ($/hour) indicator.
The dashboard must display a minimum of 90 days of historical cost data with daily granularity. Forecasting must project end-of-period spend based on current burn rate with configurable forecast horizon (7, 14, 30 days). Forecast confidence intervals must be displayed.
All cost events — budget warnings, threshold breaches, anomaly detections, cap enforcements, and routing decisions — must be published to the central governance audit bus as structured events with standardized schema. Events must be immutable once written.
Project-level budgets must automatically distribute to individual agents based on configurable allocation strategies: equal split, weighted by agent role, or dynamic (agents claim from a shared project pool). Unspent agent allocations must return to the project pool at session end.
When an agent's budget is exhausted, the system must: complete the current in-flight LLM call, checkpoint agent state to durable storage, queue remaining tasks with their full context, and emit a resumption event when budget is restored. No work in progress may be silently dropped.
Threshold alerts (warn, throttle, pause, anomaly) must be deliverable via: Slack (configurable channel per project), email (configurable recipient list), and outbound webhook (configurable URL with HMAC signature). Alert delivery must be retried up to 3× on failure with exponential backoff.
Prompt to Build It
Copy this prompt into Claude Code to scaffold the Agent Economics & Cost Governance subsystem. It references the architecture and requirements above — use it as-is or adjust cost baseline values for your environment.
You are building the Agent Economics & Cost Governance subsystem for an autonomous AI development factory targeting insurance companies. The system must implement the following components with full production code — no stubs, no TODOs: ## 1. Cost Metering Engine Create `src/economics/metering_engine.ts` that: - Intercepts every LLM API call via a wrapping proxy class `MeteredLLMClient` - Records: agent_id, session_id, project_id, feature_id, model, input_tokens, output_tokens, cache_read_tokens, latency_ms, cost_usd (computed), timestamp (ISO 8601), call_id (UUID v4) - Publishes a structured `cost_event` to the governance audit bus within 100ms of call completion - Exposes `getCostLedger(agentId: string): CostLedger` for real-time querying - Token costs (per 1M): Haiku input $0.80 / output $4.00 / cache $0.08; Sonnet input $3.00 / output $15.00 / cache $0.30; Opus input $15.00 / output $75.00 / cache $1.50 ## 2. Budget Controller Create `src/economics/budget_controller.ts` that: - Maintains in-memory budget state for all active agents and projects (backed by Redis for HA) - Enforces configurable caps: project-level (total), agent-level (per session) - Implements threshold actions at 60% (log), 80% (downgrade model tier), 90% (throttle dispatch), 100% (hard pause + checkpoint state) - Anomaly detection: if agent cost-per-task exceeds 10× its 7-day rolling average, auto-pause - Exposes `checkBudget(agentId, estimatedCost): BudgetDecision` returning ALLOW | WARN | THROTTLE | BLOCK - Implements budget inheritance: projects distribute to agents via EQUAL | WEIGHTED | POOL strategies ## 3. Model Router Create `src/economics/model_router.ts` that: - Accepts a `TaskDescriptor` (type, estimated_tokens, file_count, tool_call_count, requires_reasoning) - Returns a `RoutingDecision` (model_tier, model_id, rationale, estimated_cost_usd) - Routing rules: - estimated_tokens < 4K AND single_file → Haiku - estimated_tokens 4K–32K AND requires_reasoning=false → Sonnet - estimated_tokens > 32K OR requires_reasoning=true OR type in [ARCHITECTURE, SECURITY_REVIEW] → Opus - Manual override available with audit log entry - Logs every routing decision with signals used to the audit bus ## 4. Token Optimizer Create `src/economics/token_optimizer.ts` that: - Implements a file content cache keyed by (path, git_sha) — invalidates on commit - Implements a semantic result cache using cosine similarity (threshold 0.95) with 24h TTL - Implements context compression: when conversation exceeds 75% of model context window, summarize oldest 50% of turns into a compressed block - Implements batched tool calls: collect tool requests within a 50ms window, dispatch as batch - Records cache hits as `cost_savings_event` on the audit bus with estimated savings_usd ## 5. Chargeback Engine Create `src/economics/chargeback_engine.ts` that: - Aggregates cost ledger data by: organization → department → project → feature → agent → session - Generates monthly reports as `ChargebackReport` objects with line-item detail - Exports reports as CSV and JSON - Calculates ROI: cost_ai_usd, estimated_manual_hours (story_points × hours_per_point baseline), estimated_manual_cost_usd (hours × hourly_rate), roi_ratio (manual_cost / ai_cost) - Baselines configurable: default 4 hours/story-point, $150/hour developer rate ## 6. Economics Dashboard API Create `src/economics/dashboard_api.ts` that exposes: - GET /economics/live — real-time cost rate ($/hr), active agents, current spend vs. budget - GET /economics/projects/:id — project cost breakdown with budget status - GET /economics/agents/:id/session — current session cost by agent - GET /economics/trends?days=30 — historical daily costs with 14-day forecast - GET /economics/chargeback?month=YYYY-MM — chargeback report for period - WebSocket /economics/stream — real-time cost event stream for dashboard ## 7. Alert Dispatcher Create `src/economics/alert_dispatcher.ts` that: - Listens for threshold and anomaly events from Budget Controller - Dispatches to: Slack (webhook URL per project), email (configurable recipients via nodemailer), outbound webhook (HMAC-SHA256 signed payload) - Retries failed deliveries up to 3× with exponential backoff (1s, 2s, 4s) - Logs all alert delivery attempts (success/failure) to audit trail ## 8. Integration Wire all components in `src/economics/index.ts`: - Export a single `EconomicsLayer` class that initializes all subsystems - Accept config: `EconomicsConfig` with budget caps, model prices, cache TTLs, alert channels - All cost events must flow through the central `GovernanceAuditBus` from the governance module - Integrate with the Orchestration layer: wrap agent dispatch in `EconomicsLayer.authorizeDispatch()` ## Technical requirements: - TypeScript strict mode, no `any` types - All monetary values stored as integer cents (not floats) to avoid rounding errors - Redis for budget state (ioredis client), PostgreSQL for cost ledger (via existing DB layer) - All public methods must have JSDoc with parameter and return type documentation - Unit tests in `src/economics/__tests__/` using Vitest, ≥80% coverage - No hardcoded secrets — all config via environment variables
Design Decisions
Key architectural trade-offs made in designing the economics layer, with rationale for each choice.
Real-Time vs. Batched Cost Calculation
Insurance companies require real-time budget control. A 5-minute lag on enforcement is unacceptable when an agent can burn $50 in a single runaway session. The 3–8ms overhead is negligible against LLM call latency of 1,000–15,000ms.
Centralized vs. Distributed Metering
The current scale (10s–100s of concurrent agents) does not require distributed metering. Centralized metering through a Redis-backed Budget Controller is operationally simpler and provides the consistency guarantees needed for financial audit trails. Can be sharded horizontally if needed at 1,000+ agents.
Model Routing: Heuristics vs. Learned Routing
Insurance regulators expect explainable decision-making at every layer. An ML routing model that cannot articulate why it chose Opus for a task creates compliance risk. Heuristic rules are auditable, versioned in code, and produce deterministic routing logs. ML routing is a future enhancement after sufficient operational data is collected.
Caching Granularity: Token-Level vs. Semantic-Level
The embedding cost for semantic cache lookup (Haiku embedding, ~$0.00002 per query) is negligible against the potential savings from a full LLM call cache hit ($0.05–$2.00). Both layers together target 50–70% effective cache utilization across a mature project's workload.
Integration Points
The Economics layer does not operate in isolation — it connects to four other subsystems, each with a defined interface contract.
Orchestration Layer
Every agent dispatch call passes through EconomicsLayer.authorizeDispatch() before execution. The orchestrator provides task metadata; the economics layer returns a DispatchAuthorization containing the routed model tier, approved budget, and any active throttle flags.
Governance Layer
Budget enforcement acts as a financial governance gate — similar to compliance gates but driven by cost thresholds. All cost events, anomaly detections, cap enforcements, and routing overrides are published to the central GovernanceAuditBus as immutable, signed events.
Dashboard Layer
The Economics Dashboard API feeds real-time cost panels, historical trend charts, and ROI summaries to the operator-facing interface. The WebSocket stream at /economics/stream pushes live cost events for sub-2-second dashboard updates without polling.
Memory System
The Token Optimizer's semantic cache is built on top of the vector memory subsystem. File content cache invalidation is coordinated with the memory layer's git-SHA tracking. Context compression writes summaries back to the memory system for future session continuity without token re-cost.
Key Interface Contracts
// Core types shared across subsystem boundaries interface CostEvent { event_id: string; // UUID v4 event_type: 'llm_call' | 'tool_use' | 'external_api' | 'cache_hit'; agent_id: string; session_id: string; project_id: string; feature_id: string | null; model: string; input_tokens: number; output_tokens: number; cache_read_tokens: number; cost_cents: number; // integer cents, never float latency_ms: number; timestamp: string; // ISO 8601 } interface DispatchAuthorization { authorized: boolean; model_tier: 'haiku' | 'sonnet' | 'opus'; model_id: string; budget_remaining_cents: number; throttle_active: boolean; block_reason: string | null; } interface BudgetDecision { decision: 'ALLOW' | 'WARN' | 'THROTTLE' | 'BLOCK'; threshold_pct: number; spent_cents: number; cap_cents: number; anomaly: boolean; }
Cost-Per-Feature Tracking Flow
When a feature ticket (e.g., FEAT-142) is dispatched to the orchestrator, its ID is propagated through the feature_id field on every cost event generated during that feature's work. The Chargeback Engine aggregates all events with the same feature_id to produce the total AI cost for that feature — enabling precise cost-per-story-point metrics across your entire project backlog.