1. AI-generated code is unauditable
An LLM produces 200 lines of code. Three weeks later a defect ships to production. Nobody knows what prompt produced it, which model version, what context was in memory, or what the agent was instructed to do. The platform captures all of this as structured, queryable records.
2. Agents drift without governance
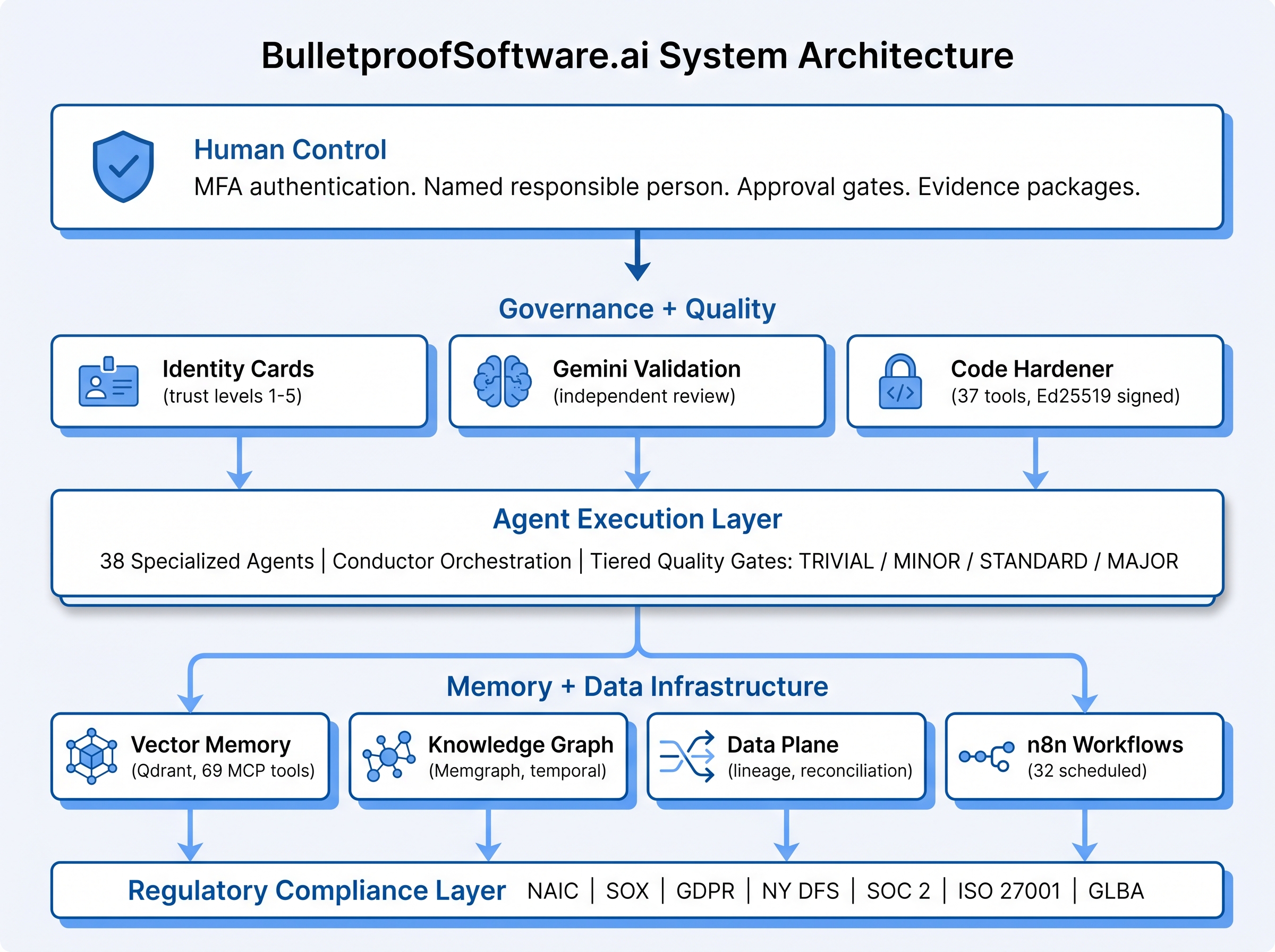
Autonomous agents can escalate privileges, exfiltrate data, ignore scope boundaries, and make decisions they shouldn't. Identity cards, tiered tool classification, constitutional contracts, and runtime policy enforcement constrain what each agent can do based on trust level and data classification.
3. Memory doesn't survive sessions
Every conversation starts from scratch. Knowledge, decisions, and successful patterns from prior work are lost. The persistent vector memory system retains semantic knowledge across sessions, with brain-inspired consolidation, hot/warm/cold tiering, and cross-project context transfer.
4. Validation is self-reported
Agents that grade their own homework claim success regardless of actual output quality. Every agent run is independently validated by a different model (Gemini validates Claude output) with structured PASS/FAIL verdicts and finding-level remediation loops.
5. Costs are invisible until the bill arrives
Token usage compounds invisibly. A runaway agent loop can consume thousands of dollars before anyone notices. Per-interaction cost tracking, four-tier budget hierarchy (org/project/agent_class/agent_instance) with warn/throttle/pause enforcement, and CPSO (Cost Per Successful Outcome) link cost to value.
6. AI-generated code fails regulatory audit
NAIC, SOX, GDPR, NY DFS Part 500, SOC 2, ISO 27001, and GLBA all require human attribution, tamper-evident audit trails, model governance documentation, and reproducible evidence. The regulatory compliance layer produces auditor-ready evidence packages from live system state without manual reconstruction.
7. Code quality gates are manual and inconsistent
Senior engineers inspect AI output before merge — but inconsistently, under time pressure, and with no systematic record. The Code Hardener platform runs 37 integrated tools across 12 scan profiles with a 6-stage enrichment pipeline, producing cryptographically signed quality reports.
8. Workflows fail silently
A pipeline runs for two hours, fails on step 9 of 12, and restarts from scratch — losing the successful work from steps 1–8. Self-healing workflow recovery classifies failures into 7 categories, resumes from checkpoints, and applies category-appropriate remediation (retry, reroute, degrade, escalate).
9. Agent systems don't interoperate
Different vendors (Anthropic, OpenAI, Google) speak different protocols. Agents can't discover or delegate to each other across systems. The A2A interoperability gateway exposes 15 conductor agents via REST, MCP Bridge, and Google A2A protocol adapters with standardized capability discovery at /.well-known/agent.json.