When autonomous agents generate insurance software, the data flowing through those systems touches policyholder PII, claims records, financial transactions, and protected health information. Without a dedicated data plane — lineage tracking, quality validation, pipeline observability, continuous classification, and source-to-target reconciliation — there is no defensible answer when a regulator asks where a data element came from, whether it was accurate, or whether calculations are mathematically consistent across systems. The Agentic Data Plane closes that gap, providing a governance-grade data infrastructure layer that operates beneath every agent-generated system.
Section 01
Problem Statement
Why autonomous agents building insurance software require a dedicated data governance layer — and what breaks without one.
🔍
The Provenance Gap
Agents generate code that transforms data — enriching quotes with bureau data, mapping claims fields, aggregating policy records. Each transformation moves data further from its source. Without lineage tracking, a state DOI examiner asking "where did this loss ratio figure come from?" receives a shrug. No DAG. No audit trail. No defensible answer.
⚠️
Silent Quality Degradation
Data quality issues in agent-generated systems accumulate silently. A null rate class propagates into a pricing model. A stale bureau score feeds a risk tier. Without automated quality validation built into the pipeline, degraded data moves to production undetected — only surfacing when a claim adjudication fails or a regulatory filing is rejected.
📡
Invisible Pipeline Changes
When agents modify upstream systems, downstream consumers have no visibility into what changed or when. A schema alteration in a policy administration system silently breaks a reporting pipeline. Pipeline observability — real-time monitoring of data flows with anomaly detection — is the only way to catch these breaks before they become compliance failures.
🏷️
Data Classification Drift
Classification at rest is insufficient when agents constantly generate new data structures. A new claims table may contain PHI the classification system never saw. A synthetic test dataset may inadvertently include real policyholder names. Continuous classification — scanning data in motion — is required to maintain HIPAA, state DOI, and NAIC compliance posture as systems evolve.
🧮
The Reconciliation Gap
When an agent transforms premium calculations from a rating engine into a policy administration system, can you prove the numbers match? Financial auditors require mathematical proof that calculations in the upstream system produce identical results in the target — not just that the data arrived, but that every subtotal, aggregation, and derived value is consistent end-to-end. Without source-to-target reconciliation, a single rounding error or silent truncation becomes an audit finding.
The core problem: Insurance carriers operating under NAIC model laws, state DOI regulations, and HIPAA must be able to demonstrate data provenance, quality, classification, and calculation integrity for every system they deploy. When those systems are agent-generated and evolving continuously, a static, periodic approach to data governance fails. The data plane must be continuous, automated, and integrated — not a quarterly audit exercise.
Section 02
Architecture Overview
Six integrated components forming a complete data governance plane for agent-generated insurance systems.
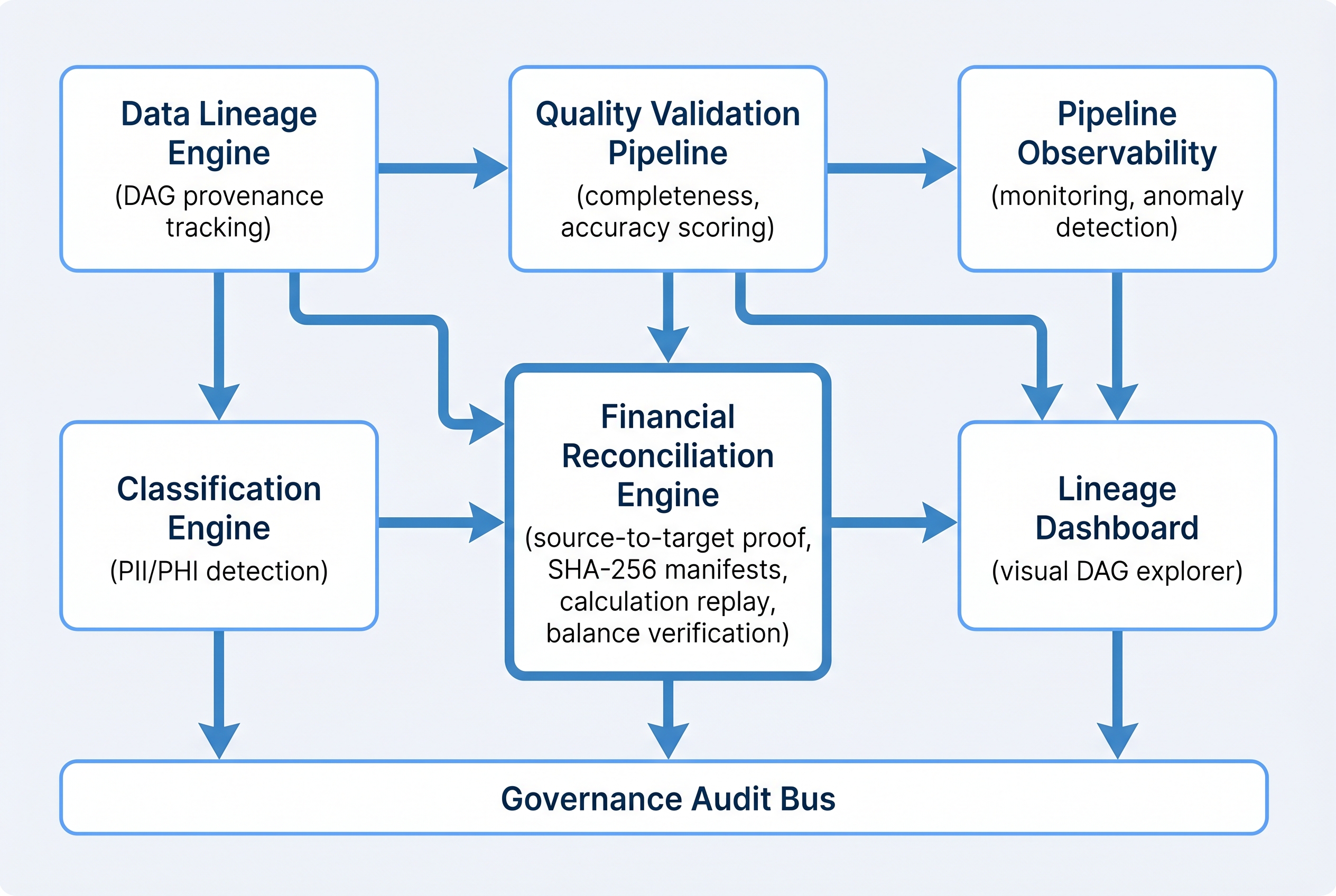
🗂️
Data Lineage Engine
DAG-based provenance tracking for every data transformation from source to output, with immutable event records.
✅
Quality Validation Pipeline
Automated scoring across completeness, accuracy, consistency, and timeliness dimensions with configurable thresholds.
📊
Pipeline Observability
Real-time monitoring of data flows with anomaly detection, schema drift alerts, and SLA tracking.
🔒
Continuous Classification Engine
In-motion PII, PHI, and regulated data detection using ML classifiers tuned for insurance data types.
🗺️
Lineage Dashboard
Visual DAG explorer tracing any output field through every transformation back to its origin source.
🧮
Financial Reconciliation Engine
Source-to-target calculation proof with SHA-256 manifests, deterministic replay, balance reconciliation, and auditor-ready reports.
Design principle: Every component publishes to the same governance audit bus used by the broader framework. Lineage events, quality alerts, classification records, reconciliation manifests, and pipeline health metrics are all first-class citizens in the audit trail — not siloed data plane concerns. A regulator pulling an audit trail sees data provenance and code provenance in the same chronological stream.
Section 03
Key Components
Detailed specifications for each component, including data classification tiers, quality scoring, lineage event types, and governance integration points.
Data Classification Tiers
Tier
Label
Insurance Data Examples
Regulatory Framework
Handling Requirements
T0
Public
Published rate filings, product brochures, aggregated industry statistics
None specific
No restrictions; may be shared freely
T1
Internal
Underwriting guidelines, internal loss ratios, agent performance metrics
Trade secret protection
Access limited to employees; not for external sharing
T2
Confidential
Policyholder name, address, policy number, premium data, claims history
Gramm-Leach-Bliley (GLBA), state DOI regulations, NAIC Privacy Model
Encryption at rest and in transit; access logging; data minimization
For regulated industries — insurance, banking, healthcare — it is not enough to track that data moved through a pipeline. Auditors require proof that calculations executed in the source system produce identical results in the target system and that mathematical integrity is preserved at every transformation stage. The reconciliation engine provides this proof.
Source-to-Target Verification
Every pipeline run produces a reconciliation manifest: a signed document containing input record counts, output record counts, and deterministic hash digests (SHA-256) of the calculation inputs and outputs at each stage. The manifest is compared against the target system's independently computed values. Any mismatch — even a single cent — is flagged as a reconciliation break and blocks downstream consumption until resolved.
Calculation Replay
The engine captures every calculation's inputs, formula/logic reference, and outputs as a reproducible computation record. Auditors can select any record and trigger a replay: the engine re-executes the calculation using the captured inputs and the current formula version, then compares the result against the stored output. Drift between formula versions is surfaced with side-by-side comparison.
Balance Reconciliation
At every aggregation boundary (subtotals, group-by rollups, grand totals), the engine independently computes control totals from the underlying detail records and compares them against the aggregated values. This catches truncation errors, floating-point drift, rounding policy inconsistencies, and silent data loss from filtered records. Tolerances are configurable per field (e.g., ±$0.01 for currency, exact match for record counts).
Auditor-Ready Reporting
Reconciliation results are published as structured reports in PDF and machine-readable JSON. Each report contains: pipeline run ID, timestamp, source system identifier, target system identifier, record counts (matched/unmatched/orphaned), control total comparisons, hash verification status, and a reconciliation verdict (PASS / PASS WITH EXCEPTIONS / FAIL). Exception details include the specific records and fields that broke, with full lineage trace back to source.
Reconciliation Flow
Stage
What Is Compared
Proof Method
Extraction
Source record count vs extracted count
Row count + SHA-256 of sort-ordered primary keys
Transformation
Input values + formula → output values
Deterministic replay with captured inputs
Aggregation
Sum of details vs reported totals
Independent control total recomputation
Loading
Staged records vs committed records
Row count + hash digest of target table snapshot
End-to-End
Source grand totals vs target grand totals
Cross-system balance comparison with tolerance
Governance Audit Bus Integration
Event Publishing
All eight lineage event types are published to the governance framework's central audit bus in real time. Events are signed with the originating agent's identity token and cannot be modified after publication. The audit bus maintains a cryptographic hash chain across events, providing tamper evidence for regulatory review.
Downstream Subscribers
The governance dashboard, compliance reporting module, and risk assessment engine all subscribe to data plane events. Classification violations trigger immediate alerts to the compliance officer workflow. Quality score drops below the blocking threshold pause pipeline promotion and notify the responsible agent orchestrator.
Section 04
Requirements
Twenty-four functional and non-functional requirements governing the Agentic Data Plane, numbered in REQ-DATA format.
REQ-DATA-001
Lineage Tracking for Every Agent Transformation
Every data transformation executed by an agent — including schema mapping, field derivation, aggregation, and enrichment — must emit a LINEAGE_TRANSFORM event before the transformation completes. Transformations without a corresponding lineage event must not be applied to production data.
REQ-DATA-002
Source-to-Output Provenance Chain
The lineage engine must maintain a complete, unbroken directed acyclic graph from every output field back to its source. A lineage query against any output field must resolve to at least one source system within 500ms for datasets up to 10 million records.
REQ-DATA-003
Quality Scoring with Configurable Thresholds
The quality validation pipeline must compute a 0–1000 point score for each dataset using four weighted dimensions: completeness, accuracy, consistency, and timeliness. Threshold values for alerts and pipeline blocking must be configurable per dataset, pipeline, and environment without code changes.
REQ-DATA-004
Production Pipeline Blocking on Quality Failure
Any dataset scoring below the configured blocking threshold (default: 700/1000) must be prevented from promotion to production environments. The blocking decision must be logged to the governance audit bus as a QUALITY_SCORED event with the specific failing dimensions identified.
REQ-DATA-005
Real-Time PII Detection in Data Pipelines
The continuous classification engine must scan all data in motion for PII and PHI at a minimum detection rate of 98.5% for the regulated field types defined in the insurance data type registry. Detection latency must not exceed 150ms per record, ensuring classification does not become a pipeline bottleneck.
REQ-DATA-006
Insurance-Specific Data Type Classifiers
The classification engine must include pre-trained classifiers for insurance-specific regulated data types: HIPAA-covered PHI fields, state DOI-regulated policyholder data, NAIC-defined financial data elements, and PCI-DSS payment card data. Classifiers must be versioned and updatable without pipeline downtime.
REQ-DATA-007
Anomaly Detection on Pipeline Outputs
The pipeline observability layer must detect and alert on four anomaly classes: schema drift (field additions, removals, type changes), volume anomalies (>2σ deviation from baseline), null rate spikes (>10% increase from baseline), and SLA breaches (processing time exceeds configured maximum). Alerts must reach subscribers within 30 seconds of detection.
REQ-DATA-008
Downstream Consumer Notification on Schema Drift
When schema drift is detected in an upstream pipeline, all registered downstream consumers must receive a structured notification including the pipeline ID, the nature of the change, the affected fields, and the detected-at timestamp. Consumers must acknowledge notifications within a configurable window or be flagged for manual review.
REQ-DATA-009
Lineage Query API
A REST and GraphQL API must expose lineage queries against the data plane. Minimum required operations: trace all inputs for a given output field; list all outputs derived from a given source; retrieve the transformation history for a dataset; and query lineage events within a time range. All API responses must include a query execution time in the response headers.
REQ-DATA-010
Governance Audit Bus Integration
All data plane events — lineage, quality, classification, and pipeline health — must be published to the governance framework's central audit bus using the shared event schema. The data plane must not maintain a separate audit trail; the governance audit bus is the single source of truth for all data governance events.
REQ-DATA-011
Visual Lineage Dashboard
A browser-based dashboard must render the lineage DAG as an interactive directed graph, supporting node expansion, edge traversal, and field-level drill-down. The dashboard must support search by output field name, dataset ID, and time range. The full lineage graph for a 1,000-node DAG must render in under 3 seconds.
REQ-DATA-012
Lineage Metadata Retention Policies
Lineage metadata must be retained for a minimum of seven years to satisfy state insurance records retention requirements (reference: NAIC Model Records Retention Act). Retention policies must be configurable per data classification tier, with Restricted-tier lineage records subject to extended retention of ten years. Deletion must require dual-authorization and generate a LINEAGE_DELETE event.
REQ-DATA-013
Data Quality Debt Tracking and Trending
The system must track quality scores over time per dataset and pipeline, computing rolling 7-day and 30-day trend lines. Datasets with declining quality trends — defined as a >5% score decrease over 30 days — must generate a proactive quality debt alert before the blocking threshold is reached, providing early warning for remediation.
REQ-DATA-014
Classification Confidence Scoring and Override
The classification engine must report a confidence score (0.0–1.0) for each classification decision. Classifications with confidence below 0.75 must be flagged for human review rather than automatically enforced. A governance officer must be able to override a classification decision with a documented rationale, which is recorded to the audit bus.
REQ-DATA-015
Agent Identity Binding in Lineage Events
Every lineage event emitted as the result of an agent action must include the agent's identity token and session ID. This binds data transformations to the specific agent instance and session that performed them, enabling forensic reconstruction of which agent — and which agent version — touched which data.
REQ-DATA-016
Regulatory Report Generation
The data plane must support on-demand generation of structured regulatory reports including: complete data lineage for a policy record (for state DOI examination), PHI handling audit trail (for HIPAA compliance review), and data quality certification report (for rate filing submissions). Reports must be exportable in PDF and machine-readable JSON formats.
REQ-DATA-017
Source-to-Target Reconciliation Manifest
Every pipeline run SHALL produce a signed reconciliation manifest containing: input record count, output record count, SHA-256 hash digests of calculation inputs and outputs at each transformation stage, and a reconciliation verdict (PASS / PASS WITH EXCEPTIONS / FAIL). Any record count or hash mismatch SHALL block downstream consumption until the break is resolved and re-reconciled.
REQ-DATA-018
Deterministic Calculation Replay
Every calculation executed in the pipeline SHALL capture its inputs, formula/logic reference (versioned), and outputs as a reproducible computation record. Auditors SHALL be able to trigger a replay of any record: the engine re-executes the calculation using the captured inputs and compares the result against the stored output. Formula version drift SHALL be surfaced with side-by-side comparison of old and current formula outputs.
REQ-DATA-019
Balance Reconciliation at Aggregation Boundaries
At every aggregation boundary (subtotals, group-by rollups, grand totals), the reconciliation engine SHALL independently recompute control totals from the underlying detail records and compare against the stored aggregated values. Tolerance thresholds SHALL be configurable per field type: exact match for record counts, configurable currency tolerance (default ±$0.01) for monetary fields, and configurable percentage tolerance for derived metrics.
REQ-DATA-020
Cross-System End-to-End Verification
The reconciliation engine SHALL compare grand totals between the source system and the target system for every pipeline run. The comparison SHALL use independently computed values from each system (not passed-through totals) to detect silent data loss, truncation errors, floating-point drift, and rounding policy inconsistencies. Breaks SHALL include the specific field, expected value, actual value, and variance amount.
REQ-DATA-021
Reconciliation Break Resolution Workflow
When a reconciliation break is detected, the engine SHALL create a structured break record containing: break ID, pipeline run ID, stage, field, expected value, actual value, variance, severity (blocking/warning), and full lineage trace from source to the point of divergence. Breaks SHALL be routable to the responsible agent orchestrator or human reviewer. Resolution (with root cause) SHALL be recorded and linked to the break record.
REQ-DATA-022
Point-in-Time Reconciliation Snapshots
The engine SHALL maintain point-in-time snapshots of reconciliation state, enabling auditors to answer: "As of date X, what was the reconciliation status of pipeline Y?" Snapshots SHALL be immutable after creation and SHALL include the full reconciliation manifest, control totals, and break status. Retention SHALL align with regulatory requirements (minimum 7 years for insurance, 5 years for SOX).
REQ-DATA-023
Auditor-Ready Reconciliation Reports
Reconciliation results SHALL be exportable as structured reports in PDF (human-readable) and JSON (machine-readable). Each report SHALL contain: pipeline run ID, timestamp, source and target system identifiers, record counts (matched/unmatched/orphaned), control total comparisons per aggregation level, hash verification status per stage, reconciliation verdict, and exception details with lineage traces. Reports SHALL be signable with the same Ed25519 attestation used by the Code Hardener.
REQ-DATA-024
Continuous Reconciliation Monitoring
The reconciliation engine SHALL support continuous mode: every pipeline execution automatically reconciles and publishes results to the governance audit bus. Reconciliation failures SHALL trigger alerts configurable by severity. A reconciliation dashboard SHALL display current status, historical trends, break frequency by pipeline/stage, and mean time to resolution. SLA: reconciliation of a 1M-record pipeline SHALL complete within 60 seconds.
Section 05
Prompt to Build It
A complete Claude Code prompt to implement the Agentic Data Plane from scratch.
Build a production-ready Agentic Data Plane for insurance software systems generated by autonomous AI agents. This is a data governance infrastructure layer that runs beneath agent-generated systems, providing lineage tracking, quality validation, pipeline observability, continuous data classification, and financial audit-grade source-to-target reconciliation. Target environment: Node.js 20+ backend with TypeScript, PostgreSQL for lineage storage, Redis for real-time event streaming, and a React + D3.js lineage dashboard.
## Core Components to Build
### 1. Data Lineage Engine
Create a lineage tracking service at `src/lineage/LineageEngine.ts`:
- Implement a directed acyclic graph (DAG) data structure for data provenance using an adjacency list with `LineageNode` and `LineageEdge` types
- `LineageNode`: { node_id: string, operation: string, agent_id: string, session_id: string, inputs: string[], outputs: string[], transform_fn: string, schema_hash: string, timestamp: ISO8601, metadata: Record }
- `LineageEdge`: { from: string, to: string, field_map: Record, transform_applied: string }
- Implement `LineageEngine.record(event: LineageEvent): Promise` — appends to both in-memory DAG and PostgreSQL persistence
- Implement `LineageEngine.trace(output_field_id: string): Promise` — backward traversal from output to all source nodes, returning the complete path with < 500ms SLA
- Implement `LineageEngine.query(filters: LineageQueryFilters): Promise` — supports filtering by time range, agent_id, source_system, and output_destination
- Persist all lineage nodes and edges in PostgreSQL tables `lineage_nodes` and `lineage_edges` with appropriate indexes on node_id, agent_id, and timestamp
- Emit all lineage events to the governance audit bus (Redis Streams topic `audit:data:lineage`)
- Enforce 7-year retention for standard data, 10-year for Restricted-tier; implement `LineageEngine.purge(before: Date, tier: DataTier)` with dual-authorization requirement (two officer tokens required)
### 2. Quality Validation Pipeline
Create `src/quality/QualityValidator.ts`:
- Implement four scoring dimensions, each 0–250 points, summing to a 0–1000 total:
- Completeness: count non-null required fields / total required fields, weighted by field criticality
- Accuracy: validate values against reference datasets (NAIC codes, ISO codes, VIN patterns, ZIP+4 format)
- Consistency: check cross-field business rules (effective_date < expiry_date, premium > 0, deductible <= limit, valid state/LOB combinations)
- Timeliness: freshness_score = max(0, 250 * (1 - data_age_hours / sla_hours))
- Implement `QualityValidator.score(dataset: Dataset, config: QualityConfig): Promise`
- `QualityScore`: { dataset_id, total_score, completeness, accuracy, consistency, timeliness, failing_checks: FailingCheck[], timestamp }
- Implement threshold enforcement: if total_score < config.blocking_threshold (default 700), reject promotion with `QualityBlockError` and publish `audit:data:quality` event
- Implement trend tracking: store score history in PostgreSQL `quality_scores` table; compute 7-day and 30-day rolling averages; emit `QUALITY_DEBT_ALERT` when 30-day trend shows > 5% decline before blocking threshold is reached
- Expose `QualityValidator.report(dataset_id: string, from: Date, to: Date): Promise` for regulatory report generation
### 3. Pipeline Observability Layer
Create `src/observability/PipelineObserver.ts`:
- Register pipelines with `PipelineObserver.register(pipeline: PipelineDefinition)` — stores baseline schema, expected volume range, null rate baselines, and SLA config
- Implement real-time monitoring via `PipelineObserver.observe(pipeline_id: string, batch: DataBatch): Promise`:
- Schema drift: deep-compare current schema to baseline; detect field additions, removals, type changes, and required/optional status changes
- Volume anomaly: compare batch record count to rolling 30-day baseline; flag if deviation > 2σ
- Null rate spike: compute per-field null rates; flag any field with > 10% increase from baseline
- SLA breach: measure processing time; flag if exceeds `pipeline.max_processing_ms`
- On anomaly detection: emit `PipelineAlert` to Redis Streams topic `audit:data:pipeline`; notify all registered downstream consumers via webhook with retry (3 attempts, exponential backoff)
- Consumers acknowledge via `PipelineObserver.acknowledge(pipeline_id: string, consumer_id: string, alert_id: string)` — unacknowledged alerts after configurable TTL escalate to manual review queue
### 4. Continuous Classification Engine
Create `src/classification/ClassificationEngine.ts`:
- Implement field-level classification scanning for data in motion
- Build pattern-matching + ML hybrid classifiers for:
- PII: SSN (XXX-XX-XXXX pattern + Luhn-variant check), DOB, name+address combos, email, phone
- PHI (HIPAA): medical record numbers, diagnosis codes (ICD-10 format), treatment dates co-located with patient identifiers, provider NPI numbers
- Financial: payment card numbers (Luhn validation), bank account numbers, routing numbers
- Insurance-specific NAIC fields: NAIC company codes, FEIN/TIN in insurance context, adjuster license numbers, DOI filing reference numbers
- Each classifier returns `ClassificationResult { field_path, detected_tier: DataTier, detected_type: string, confidence: number (0.0-1.0), evidence: string[] }`
- Classifications with confidence < 0.75 are flagged `NEEDS_REVIEW` rather than auto-enforced
- Implement `ClassificationEngine.scan(data_stream: AsyncIterable): AsyncIterable` — streaming API, max 150ms latency per record
- Publish all classification results to `audit:data:classification` Redis Stream
- Implement override API: `ClassificationEngine.override(result_id: string, new_tier: DataTier, rationale: string, officer_token: string)` — records override to audit bus with officer identity
### 5. Lineage Query REST + GraphQL API
Create `src/api/LineageAPI.ts` using Express + Apollo Server:
REST endpoints:
- `GET /api/v1/lineage/trace/:output_field_id` — full backward trace to sources
- `GET /api/v1/lineage/sources/:source_id/outputs` — all outputs derived from a source
- `GET /api/v1/lineage/datasets/:dataset_id/history` — transformation history
- `GET /api/v1/lineage/events?from=&to=&agent_id=&pipeline_id=` — time-range event query
- `GET /api/v1/lineage/report/:policy_id` — regulatory lineage report for a policy record
- `GET /api/v1/quality/datasets/:dataset_id/trend?days=30` — quality trend report
- `POST /api/v1/reports/regulatory` — generate formatted regulatory report (PDF/JSON)
GraphQL schema: expose `lineageTrace`, `lineageSearch`, `qualityScore`, `classificationHistory`, `pipelineHealth` queries with full type definitions.
All API responses must include `X-Query-Time-Ms` header. Authentication via JWT with role-based access (viewer, analyst, compliance_officer, admin).
### 6. Lineage Dashboard
Create `src/dashboard/` as a React + TypeScript SPA:
- Use D3.js for DAG visualization; render nodes as rectangles with color-coded tiers (T0=gray, T1=blue, T2=orange, T3=red)
- Support interactive features: node click to expand/collapse; edge hover to show transform details; field-level drill-down panel
- Search bar: query by output field name, dataset ID, time range; results highlight matching subgraph
- Performance: 1,000-node DAG must render in < 3 seconds using WebWorker for layout computation
- Quality panel: show sparkline of 30-day quality trend per selected dataset
- Pipeline health panel: show last 24h of pipeline observations with anomaly indicators
- Classification coverage: show heatmap of classification tier distribution across active pipelines
### 7. Governance Audit Bus Integration
Create `src/audit/AuditBusClient.ts`:
- Wrap Redis Streams with typed publish methods for each event type
- Implement `AuditBusClient.publish(event: AuditEvent): Promise` with retry logic (3 attempts) and dead-letter queue for failed publishes
- Sign all events with HMAC-SHA256 using the service's private key before publishing — consumers can verify integrity
- Implement hash-chained event IDs: each event's ID incorporates a hash of the previous event in the stream, providing tamper evidence
- Subscribe methods: `AuditBusClient.subscribe(topic: string, handler: EventHandler): () => void` — returns unsubscribe function
### 8. Financial Reconciliation Engine
Create `src/reconciliation/ReconciliationEngine.ts`:
- Implement `ReconciliationEngine.reconcile(pipelineRunId: string): Promise<ReconciliationManifest>` — compares source and target at every stage
- At extraction: compare source record count vs extracted count, SHA-256 of sort-ordered primary keys
- At transformation: capture inputs + formula reference + outputs as `ComputationRecord`, support deterministic replay via `ReconciliationEngine.replay(recordId: string)`
- At aggregation: independently recompute control totals from detail records, compare against stored aggregates with configurable tolerance (exact for counts, ±$0.01 for currency)
- At loading: compare staged record count/hash vs committed count/hash in target system
- End-to-end: compare source grand totals vs target grand totals using independently computed values
- `ReconciliationManifest`: { run_id, timestamp, source_system, target_system, stages: StageResult[], record_counts: { source, target, matched, unmatched, orphaned }, control_totals: ControlTotal[], verdict: 'PASS' | 'PASS_WITH_EXCEPTIONS' | 'FAIL', breaks: Break[], signature: Ed25519Signature }
- Break resolution: `ReconciliationEngine.resolveBreak(breakId: string, rootCause: string): Promise<void>` — records resolution with lineage trace
- Continuous mode: auto-reconcile on every pipeline run, publish results to audit bus topic `audit:data:reconciliation`
- Report generation: `ReconciliationEngine.generateReport(manifestId: string, format: 'pdf' | 'json'): Promise<Buffer>`
- Point-in-time snapshots: immutable, queryable by date range, minimum 7-year retention for insurance compliance
- Reconciliation dashboard: current status, historical trends, break frequency, MTTR per pipeline
- SLA: reconciliation of 1M-record pipeline completes within 60 seconds
## Database Schema (PostgreSQL)
Create migration files in `migrations/`:
```sql
-- Lineage nodes
CREATE TABLE lineage_nodes (
node_id UUID PRIMARY KEY,
operation VARCHAR(100) NOT NULL,
agent_id VARCHAR(100) NOT NULL,
session_id VARCHAR(100) NOT NULL,
schema_hash VARCHAR(64),
tier VARCHAR(20),
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
metadata JSONB
);
CREATE INDEX idx_lineage_nodes_agent ON lineage_nodes(agent_id);
CREATE INDEX idx_lineage_nodes_created ON lineage_nodes(created_at);
-- Lineage edges
CREATE TABLE lineage_edges (
edge_id UUID PRIMARY KEY,
from_node UUID REFERENCES lineage_nodes(node_id),
to_node UUID REFERENCES lineage_nodes(node_id),
field_map JSONB,
transform_applied TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_lineage_edges_from ON lineage_edges(from_node);
CREATE INDEX idx_lineage_edges_to ON lineage_edges(to_node);
-- Quality scores
CREATE TABLE quality_scores (
score_id UUID PRIMARY KEY,
dataset_id VARCHAR(200) NOT NULL,
pipeline_id VARCHAR(200),
total_score SMALLINT NOT NULL,
completeness SMALLINT,
accuracy SMALLINT,
consistency SMALLINT,
timeliness SMALLINT,
failing_checks JSONB,
scored_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_quality_dataset ON quality_scores(dataset_id, scored_at DESC);
-- Classification records
CREATE TABLE classification_records (
record_id UUID PRIMARY KEY,
field_path TEXT NOT NULL,
pipeline_id VARCHAR(200),
detected_tier VARCHAR(20) NOT NULL,
detected_type VARCHAR(100),
confidence NUMERIC(4,3),
status VARCHAR(20) DEFAULT 'AUTO',
override_rationale TEXT,
override_officer VARCHAR(100),
detected_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_classification_pipeline ON classification_records(pipeline_id, detected_at DESC);
```
## Configuration
Use environment variables for all configuration. Provide a `.env.example` with all required variables:
- `DATABASE_URL`, `REDIS_URL`, `AUDIT_BUS_SERVICE_KEY`
- `QUALITY_BLOCKING_THRESHOLD` (default: 700)
- `CLASSIFICATION_MIN_CONFIDENCE` (default: 0.75)
- `LINEAGE_RETENTION_YEARS_STANDARD` (default: 7)
- `LINEAGE_RETENTION_YEARS_RESTRICTED` (default: 10)
- `PIPELINE_ANOMALY_SIGMA_THRESHOLD` (default: 2.0)
## Testing Requirements
- Unit tests for all validators, classifiers, and lineage traversal logic (Jest)
- Integration tests for API endpoints using supertest with a test database
- Performance test: lineage trace on 1M-node DAG must complete in < 500ms
- Classification accuracy test: run built-in test corpus of 500 labeled insurance records; assert > 98.5% detection rate for T3 fields
## Deliverables
1. Complete TypeScript source with no stubs or TODOs
2. Docker Compose file with PostgreSQL, Redis, API service, and dashboard
3. Database migration files
4. API documentation (OpenAPI 3.0 YAML)
5. README with setup instructions, environment variable reference, and regulatory compliance notes
6. Test suite with > 90% coverage on core components
Do not use any hardcoded secrets. All sensitive configuration via environment variables. No arbitrary code execution from user input in the lineage or classification APIs.
Section 06
Design Decisions
Key architectural trade-offs considered during the design of the Agentic Data Plane.
DAG vs. Linear Lineage Model
Option ALinear chain — each transformation points to a single predecessor. Simple to implement, fast to query, low storage overhead.
Option BDirected Acyclic Graph — nodes can have multiple parents (data merges) and multiple children (data forks). Models real insurance data pipelines accurately. Chosen
RationaleInsurance data pipelines routinely merge streams: a policy record combines bureau data, application data, and prior carrier history. A linear model cannot represent this accurately. The added query complexity of DAG traversal is acceptable given the regulatory requirement for complete provenance.
Real-Time vs. Batch Classification
Option ABatch classification — scan data at rest on a scheduled interval. Lower compute cost, simpler infrastructure, no pipeline latency impact.
Option BIn-motion classification — scan every record as it transits the pipeline. Immediate detection, no window of unclassified regulated data in flight. Chosen
RationaleBatch classification creates a compliance window: regulated data can exist in an unclassified state for hours. For HIPAA and state DOI purposes, the moment PHI enters an agent-generated pipeline it must be classified and handled appropriately. The 150ms per-record latency constraint is achievable with pattern matching and a lightweight ML model without blocking throughput.
Quality Scoring Approach
Option ABinary pass/fail per dimension. Simple, deterministic, easy to explain to regulators.
Option B0–1000 continuous score with weighted dimensions. Mirrors the code quality scoring system; allows trending; supports graduated response policies. Chosen
RationaleA binary pass/fail system provides no early warning capability. By mirroring the 1000-point system used in code quality, operators gain a unified mental model across both code and data quality. The continuous score enables proactive quality debt alerts before failures occur — critical for insurance systems where a data quality failure on a rate filing can delay a product launch by months.
Option BPostgreSQL with adjacency list — standard relational model, easier operational management, broad ecosystem support, recursive CTEs for traversal. Chosen
RationaleMost insurance IT teams operate PostgreSQL. Introducing a dedicated graph database adds operational complexity (new backup procedures, new DBA skills, new monitoring) that is difficult to justify for a single use case. PostgreSQL recursive CTEs with proper indexes achieve sub-500ms traversal on the DAG sizes typical of insurance system lineage. If traversal performance degrades at scale, migration to a graph backend remains an option.
Audit Event Integrity
Option AStandard append-only log with timestamps. Relies on infrastructure-level access controls to prevent tampering.
Option BHash-chained event stream with HMAC signing. Each event's ID incorporates a hash of the previous event; tampering with any event breaks the chain. Chosen
RationaleState DOI examinations and HIPAA audits may specifically ask whether audit records have been modified. Hash chaining provides cryptographic evidence of integrity without requiring a blockchain — it is tamper-evident, not tamper-proof, but provides the evidentiary standard required for regulatory examination.
Classification ML vs. Pattern Matching
Option APure regex/pattern matching. Fully deterministic, auditable, no model drift, easy to explain false positives to compliance.
Option BHybrid: pattern matching for high-confidence structured fields (SSN, credit card), ML for contextual detection of unstructured PHI and insurance-specific regulated data. Chosen
RationalePattern matching alone misses PHI in free-text fields — a claims adjuster note containing a diagnosis is not detectable by regex. The hybrid approach uses patterns for structured fields (deterministic, zero false negatives on known formats) and ML for contextual detection in unstructured text. The 0.75 confidence threshold ensures low-confidence ML results go to human review rather than auto-enforcement.
Section 07
Integration Points
How the Agentic Data Plane connects to the other ten BulletproofSoftware.ai components.
Memory System
Vector Memory Lineage
When agents store embeddings or retrieve memories that inform data transformations, those memory operations are recorded as lineage nodes. If an agent uses a retrieved policy template to generate a new claims form, the memory retrieval event becomes a source node in the lineage DAG. This creates a complete provenance chain from institutional knowledge through to generated output — critical for explaining why a system was built a certain way during a regulatory examination.
Governance Framework
Audit Bus and Classification Tiers
The data plane is a first-class publisher on the governance framework's central audit bus. All eight lineage event types, quality scores, classification results, and pipeline health events flow into the same audit trail as code governance events. The data classification tiers (T0–T3) defined in the data plane are the authoritative classification system referenced by all other framework components — not a separate data-plane-specific taxonomy.
Code Assurance
Data Validation in Generated Code
When the code assurance system reviews agent-generated code, it validates that data access patterns comply with the classification tier of the data being accessed. Code that reads T3 (Restricted) fields without the appropriate access pattern annotations fails the code quality gate. The data plane's classification registry is the reference source for these code-level checks — the two systems share a classification schema rather than maintaining independent taxonomies.
Dashboard
Lineage Visualization
The BulletproofSoftware.ai master dashboard embeds the lineage DAG viewer as a panel, with drill-down links from any system component to its data lineage. A compliance officer viewing the governance dashboard can click on any generated system and navigate directly to its data lineage explorer without switching contexts. The dashboard also surfaces the 30-day quality trend sparklines and classification coverage heatmap as top-level metrics alongside code quality and deployment frequency.
Agent Orchestrator
Pipeline Blocking Integration
When the quality validation pipeline blocks a dataset from production promotion, it signals the agent orchestrator via a structured event on the audit bus. The orchestrator can respond by pausing dependent agents, triggering a data remediation workflow, or escalating to a human operator. The blocking threshold is configurable per pipeline context — a regulatory filing pipeline may have a stricter threshold than an internal analytics pipeline.
Regulatory Reporting
Examination-Ready Reports
State DOI examinations, HIPAA audits, and NAIC data calls require specific data provenance documentation. The data plane's regulatory report generation endpoint produces structured reports in the format expected by each regulatory body, drawing on the lineage DAG, classification records, and quality history. These reports are generated on-demand and do not require manual data assembly by compliance staff — reducing examination response time from weeks to hours.