Event-Driven Automation.
Centralized event taxonomy, routing engine, and workflow orchestration that transforms invisible n8n automation infrastructure into a structured, observable, and governable event-driven system.
1Problem Statement
The system currently operates 32 n8n automation workflows that handle critical operational functions: memory consolidation, session persistence, infrastructure monitoring, notification dispatch, security scanning, and more. These workflows exist as invisible infrastructure -- they run in the background, triggered by webhooks and cron schedules, with no centralized visibility into their health, no standardized event format, and no integration with the conductor's workflow state.
This invisible infrastructure creates three systemic problems:
- No event taxonomy: Each workflow defines its own trigger format, payload structure, and naming conventions. A "session started" event from one workflow looks entirely different from a "session started" event consumed by another. There is no shared vocabulary for system events, making it impossible to build cross-cutting automation (e.g., "when any security event occurs, also trigger the audit workflow").
- No conductor state integration: n8n workflows operate independently of the conductor orchestrator. When the conductor dispatches agents and manages workflow state, n8n automation runs in a parallel universe. There is no mechanism for conductor state changes to trigger n8n workflows or for n8n workflow results to update conductor state. This creates blind spots where the orchestrator does not know about actions taken by background automation.
- No systematic trigger patterns: Workflow triggers are ad-hoc -- some use webhooks, some use cron schedules, some are manually invoked. There is no routing layer that can direct a single event to multiple workflows, handle failed deliveries, or provide dead-letter semantics for events that could not be processed. Failed events are silently lost.
The result is fragile automation that works when everything goes right but provides no observability, no recovery, and no governance when things go wrong. An event-driven architecture with a centralized taxonomy and routing engine transforms this invisible infrastructure into a structured, observable, and manageable system.
Scale of the Problem
The 15 existing n8n workflows collectively process an estimated 500-1,000 events per day across all trigger types. Without centralized routing, each workflow independently handles its own error cases, retry logic, and logging. This results in duplicated logic across workflows, inconsistent error handling, and no aggregate view of event processing health. When a workflow silently fails, the only indication is the absence of its expected side effect -- which may not be noticed for hours or days.
As the system grows (new agents, new integrations, new operational requirements), the number of workflows will increase. Without an event-driven foundation, each new workflow adds another piece of invisible, ungoverned infrastructure. The event-driven architecture creates the foundation that makes future automation sustainable.
2Architecture
The Event-Driven Automation system introduces a central Event Router that sits between event producers (conductor, agents, hooks, cron, external services) and event consumers (n8n workflows, conductor state updates, direct actions). Every event in the system flows through the router, which applies routing rules to determine which consumers should receive each event.
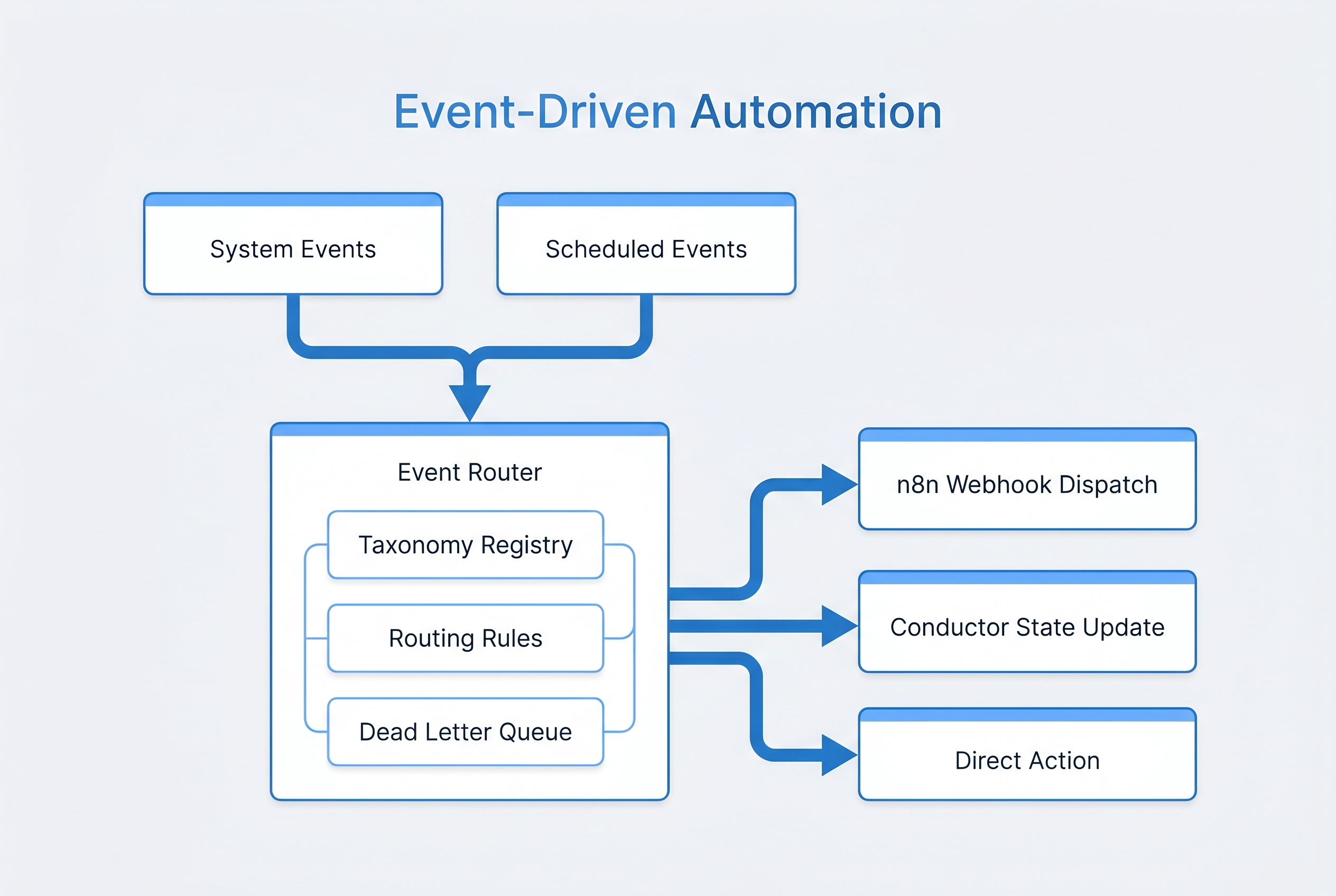
System Flow
Event producers emit structured events conforming to the event taxonomy. Each event includes a category, type, payload, source identifier, timestamp, and correlation ID. The Event Router receives the event, evaluates it against the YAML-defined routing rules, and dispatches it to all matching consumers. Dispatching uses fire-and-forget semantics -- the producer does not wait for consumer acknowledgment. If a consumer fails to process an event, the event is moved to the Dead Letter Queue for retry or manual intervention.
Event Taxonomy
The taxonomy defines 10 top-level event categories, each with specific event types:
Core Components
Event Router
Central dispatch engine that evaluates events against YAML-defined routing rules. Supports fan-out (one event to multiple consumers), filtering (route only events matching specific criteria), and priority ordering (high-priority consumers receive events first). The router is stateless -- it does not store events, only routes them.
Taxonomy Registry
YAML-defined schema for all event categories and types. Validates incoming events against the taxonomy before routing. Rejects events with unknown categories or types, preventing unstructured data from entering the system. The registry is the single source of truth for the event vocabulary.
Workflow Registry
Catalog of all 32 n8n workflows with metadata: trigger type, expected events, SLA (maximum acceptable processing time), health status, last execution timestamp, and failure rate. The registry enables the health dashboard and provides the data for SLA monitoring.
Dead Letter Queue
SQLite-backed queue for events that failed consumer delivery. Stores the original event, the target consumer, the failure reason, and the number of retry attempts. Supports manual replay (re-dispatch a specific event), bulk replay (re-dispatch all events for a time range), and automatic retry with configurable backoff.
Workflow Health Dashboard
Real-time visibility into workflow execution health. Displays per-workflow metrics: success rate, average processing time, SLA compliance, DLQ depth, and last execution status. Aggregates across all workflows to provide system-level health indicators. Triggers alerts when SLA violations or elevated failure rates are detected.
Routing Rules
Routing rules are defined in YAML and evaluated in priority order. Each rule specifies: a match condition (event category, type, and optional payload filters), one or more target consumers, delivery priority, and retry policy. Rules support glob patterns for flexible matching (e.g., security.* matches all security events).
Example routing semantics:
- All
agent.failevents route to both the self-healing engine and the notification workflow - All
governance.*events route to the audit trail workflow - All
security.vulnerability_foundevents with severity "critical" route to the immediate alert workflow with high priority - All
session.endevents route to the memory consolidation workflow and the session metrics workflow
Consumer Types
The router supports three consumer types, each with different delivery semantics:
- n8n Webhook: HTTP POST to an n8n webhook endpoint. Fire-and-forget with DLQ on HTTP error. This is the primary consumer type for most automation.
- Conductor State Update: Direct modification of conductor-state.json. Used for events that need to update orchestration state (e.g., recording agent completion events in the workflow timeline).
- Direct Action: Inline execution of a simple action (file write, command execution, memory store). Used for lightweight reactions that do not warrant a full n8n workflow.
3Requirements
| ID | Requirement | Priority | Acceptance Criteria |
|---|---|---|---|
REQ-ED-001 |
Event Taxonomy must define exactly 10 top-level categories with typed event schemas | HIGH | Each category has a YAML schema definition; events are validated against schema before routing; unknown categories are rejected |
REQ-ED-002 |
Event Router must support YAML-defined routing rules with glob pattern matching | HIGH | Rules support category.type patterns including wildcards; rules evaluated in priority order; fan-out to multiple consumers |
REQ-ED-003 |
All 15 existing n8n workflows must be cataloged in the Workflow Registry with metadata | HIGH | Each workflow entry includes: name, trigger type, subscribed events, SLA, health status, last execution time |
REQ-ED-004 |
Dead Letter Queue must use SQLite for persistent storage with replay capability | HIGH | Failed events stored with original payload, target, failure reason, retry count; supports single and bulk replay; automatic retry with backoff |
REQ-ED-005 |
Event dispatch must use fire-and-forget semantics -- producers never block on consumer acknowledgment | HIGH | Event emission returns immediately; consumer failures are handled asynchronously via DLQ; producer latency unaffected by consumer performance |
REQ-ED-006 |
Every event must include: category, type, payload, source, timestamp, and correlation ID | HIGH | Events missing required fields are rejected at the router; correlation ID enables tracing events across consumers |
REQ-ED-007 |
Workflow Health Dashboard must display per-workflow and aggregate metrics in real time | MEDIUM | Dashboard shows: success rate, avg processing time, SLA compliance, DLQ depth, last status for each workflow and system-wide |
REQ-ED-008 |
Each workflow must have a defined SLA with automated violation alerting | MEDIUM | SLA defined in seconds per workflow; violations trigger alert events; SLA compliance tracked over rolling 24-hour windows |
REQ-ED-009 |
Router must support three consumer types: n8n webhook, conductor state update, and direct action | HIGH | Each consumer type has defined delivery semantics; n8n uses HTTP POST; state update modifies JSON; direct action executes inline |
REQ-ED-010 |
Event routing rules must be hot-reloadable without system restart | MEDIUM | YAML routing rules can be modified and reloaded at runtime; new rules take effect for the next event; no event loss during reload |
REQ-ED-011 |
DLQ must support configurable retention with automatic purge of aged entries | LOW | Default retention: 30 days; configurable per event category; purge runs on schedule; purge events logged |
REQ-ED-012 |
All event routing decisions must be logged for audit and debugging | MEDIUM | Routing log includes: event ID, matched rules, target consumers, delivery status; queryable by event ID and time range |
REQ-ED-013 |
Event Router must handle at least 100 events per second without degradation | MEDIUM | Load test demonstrates 100 events/second with p99 routing latency under 50ms; no event loss under load |
REQ-ED-014 |
Correlation IDs must propagate across event chains for end-to-end tracing | HIGH | When a consumer emits a follow-on event, the original correlation ID is preserved; trace query returns full event chain |
4Design Decisions
-
Fire-and-Forget Over Request-Reply Event dispatch uses fire-and-forget semantics rather than request-reply. Producers emit events and continue immediately without waiting for consumer acknowledgment. This prevents slow consumers from blocking producers and eliminates coupling between event producers and consumers. The tradeoff is that producers do not know if their events were successfully processed -- but this is acceptable because the DLQ provides eventual delivery guarantees and the audit log provides observability. Request-reply was rejected because it would introduce cascading latency when a single consumer is slow, affecting all producers.
-
YAML Routing Rules Over Code-Defined Routes Routing rules are defined in YAML configuration rather than hardcoded in the router implementation. This allows operators to add, modify, and remove routes without code changes. YAML rules are versionable, diffable, and can be reviewed in pull requests. The hot-reload capability means routing changes take effect without system restart. Code-defined routes were rejected because they would require deployment cycles for simple routing changes and would mix routing policy with routing logic.
-
SQLite Dead Letter Queue Over Redis or Message Queue The DLQ uses SQLite rather than Redis, RabbitMQ, or another message queue. SQLite provides durable, queryable storage with zero operational overhead -- no additional services to deploy, monitor, or maintain. At the current event volume (500-1,000 events/day), SQLite handles the load with margin to spare. If event volume grows beyond SQLite's capabilities (roughly 10,000+ writes/second), migration to a dedicated message queue would be warranted. The tradeoff is reduced throughput compared to Redis, but the system's current scale does not require it.
-
n8n as Execution Engine Over Custom Workflow Engine Rather than building a custom workflow execution engine, the system uses n8n as its execution substrate. n8n provides a visual workflow builder, 400+ pre-built integrations, error handling, and execution logging out of the box. The Event Router dispatches events to n8n via webhooks; n8n handles the actual workflow execution. This leverages existing infrastructure investment rather than duplicating functionality. The tradeoff is dependency on n8n's availability and performance characteristics.
-
10 Event Categories Over Flat Event Namespace Events are organized into 10 hierarchical categories rather than a flat namespace. This enables glob-pattern routing (e.g.,
security.*), simplifies governance policies (e.g., "all governance events require audit logging"), and provides natural organization for the health dashboard. A flat namespace would be simpler but would not support category-level routing or governance rules. The 10 categories were derived from analysis of existing workflow triggers and anticipated future event sources. -
SLA Per Workflow Over Global SLA Each workflow has an individually defined SLA rather than a single global processing time target. This reflects the reality that different workflows have different latency requirements -- a security alert must be processed in seconds, while a weekly memory consolidation can take minutes. Global SLAs would either be too tight for slow workflows (generating false violations) or too loose for fast workflows (missing genuine degradation). Per-workflow SLAs enable precise monitoring.
5Integration Points
| System | PRD | Integration Type | Description |
|---|---|---|---|
| Conductor Orchestrator | PRD 2 | Bidirectional | Conductor emits agent lifecycle events (dispatch, complete, fail). Event Router can update conductor-state.json via state update consumers. Conductor state changes trigger events that route to n8n workflows. |
| Governance Framework | PRD 5 | Event Producer/Consumer | Governance gate events (pass, fail, approval) are emitted as governance category events. The audit trail workflow consumes all governance events. Policy violations trigger alert events routed to notification workflows. |
| Memory System | PRD 4 | Event Producer | Memory operations (store, recall, consolidate, prune) emit memory category events. These events trigger analytics workflows and consolidation schedules. Session end events trigger memory persistence workflows. |
| Self-Healing Workflows | PRD 12 | Event Consumer | Recovery events from the self-healing engine are routed through the event system. The event router dispatches failure events to both the self-healing engine and notification workflows, enabling parallel recovery and alerting. |
| Runtime Security | PRD 11 | Event Producer | Security scans, vulnerability detections, and alert events flow through the event system. Critical security events receive priority routing to immediate notification workflows. |
| Memory Dashboard | PRD 6 | Event Consumer | Dashboard consumes memory events for real-time display of memory operations, consolidation status, and storage metrics. Events provide the live data feed for dashboard widgets. |
| n8n Workflows | External | Execution Engine | All 15 cataloged workflows receive events via webhook triggers. n8n handles execution, error handling, and logging. Workflow completion events are emitted back to the event system for tracking. |
| Agent Economics | PRD 10 | Event Consumer | Agent dispatch and completion events carry cost metadata. Agent Economics consumes these events to track spending, update budgets, and trigger cost alerts when thresholds are approached. |
6Prompt to Build It
The following prompt can be used to instruct Claude Code to build the Event-Driven Automation system. It encapsulates the full specification from this PRD.
Build an event-driven automation system with centralized event taxonomy, routing engine, and workflow orchestration for multi-agent infrastructure. Core components to implement: 1. EVENT TAXONOMY — 10 top-level categories with typed event schemas: - Session (start, end, compact, context_threshold, resume) - Memory (store, recall, consolidate, prune, promote, forget) - Agent (dispatch, complete, fail, retry, escalate, validate) - Governance (gate_pass, gate_fail, approval_request, audit_event, policy_violation) - Security (scan_start, scan_complete, vulnerability_found, remediation, alert) - Infrastructure (health_check, degradation, recovery, resource_warning, outage) - Schedule (cron_trigger, scheduled_task, maintenance_window, backup) - Git (commit, push, branch_create, pr_open, pr_merge, conflict) - External (webhook_receive, api_call, notification, third_party_event) - Recovery (failure_detected, strategy_selected, recovery_attempt, recovery_outcome) Each event must include: category, type, payload, source, timestamp (ISO 8601), and correlation_id (UUID v4). Define schemas in YAML. 2. EVENT ROUTER — Central dispatch engine: - YAML-defined routing rules evaluated in priority order - Support glob pattern matching on category.type (e.g., security.* matches all security events) - Fan-out: one event dispatched to multiple consumers - Fire-and-forget: producers never block on consumer acknowledgment - Three consumer types: n8n webhook (HTTP POST), conductor state update (JSON modification), direct action (inline execution) - Hot-reloadable rules: modify YAML and reload without restart - Target throughput: 100 events/second, p99 routing latency under 50ms 3. WORKFLOW REGISTRY — Catalog of 32 n8n workflows: - Each entry: name, description, trigger type, subscribed events, SLA (seconds), health status, last execution time, failure rate - SLA defined per workflow (security alerts: 5s, consolidation: 300s, etc.) - Health status computed from rolling 24-hour success rate - Registry defined in YAML, queryable via API 4. DEAD LETTER QUEUE — SQLite-backed failed event storage: - Store: original event, target consumer, failure reason, retry count, timestamps - Single event replay: re-dispatch a specific DLQ entry - Bulk replay: re-dispatch all entries for a time range or category - Automatic retry: configurable backoff (default: 3 attempts, exponential backoff) - Retention: 30 days default, configurable per category, automatic purge 5. WORKFLOW HEALTH DASHBOARD — Real-time monitoring: - Per-workflow metrics: success rate, avg processing time, SLA compliance, DLQ depth, last status - System-wide aggregates: total events/day, overall success rate, active DLQ entries - SLA violation alerts: triggered when a workflow exceeds its SLA - Failure rate alerts: triggered when failure rate exceeds configurable threshold Design constraints: - Fire-and-forget semantics — never block producers - Events validated against taxonomy before routing — reject unknown categories/types - Correlation IDs propagate across event chains for end-to-end tracing - Routing log records every routing decision for audit - SQLite DLQ — zero operational overhead, sufficient for current scale - n8n is the execution engine — do not rebuild workflow execution - YAML for all configuration (taxonomy, routing rules, workflow registry, SLAs) - All event routing integrates with the governance audit bus File locations: - Event taxonomy: ~/.claude/events/taxonomy.yaml - Routing rules: ~/.claude/events/routing-rules.yaml - Workflow registry: ~/.claude/events/workflow-registry.yaml - DLQ database: ~/.claude/events/dead-letter-queue.sqlite - Router implementation: ~/.claude/events/router.py - Health dashboard: ~/.claude/events/dashboard/ Integration points: - Conductor orchestrator (bidirectional — emit and consume agent events) - Governance framework (emit gate events, consume for audit) - Memory system (emit memory operation events) - Self-healing engine (route failure events for recovery) - Runtime security (route security events with priority) - n8n (webhook delivery to all 32 workflows) - Agent Economics (cost tracking via agent events)
7Implementation Notes
Phased Delivery
The event-driven system should be delivered in three phases:
- Phase 1 — Foundation (Week 1-2): Implement the event taxonomy YAML schemas, the core Event Router with YAML routing rules, and basic n8n webhook delivery. Catalog all 15 existing workflows in the Workflow Registry. This phase provides the structural foundation without disrupting existing workflows.
- Phase 2 — Reliability (Week 3-4): Add the SQLite Dead Letter Queue with retry logic, correlation ID propagation, and routing audit logging. Migrate existing n8n webhook triggers to route through the Event Router. This phase ensures reliable event delivery with recovery capability.
- Phase 3 — Observability (Week 5-6): Build the Workflow Health Dashboard, implement SLA monitoring with alerting, add conductor state update consumers, and enable hot-reload for routing rules. This phase provides the operational visibility that makes the event system manageable at scale.
Migration Strategy
Existing n8n workflows must be migrated to the event-driven model without disruption. The migration follows a shadow-then-cutover approach:
- Shadow phase: The Event Router dispatches events to n8n webhooks in parallel with existing direct triggers. Both paths deliver events; the n8n workflow only processes events from its original trigger. This validates routing correctness without risk.
- Validation phase: Compare event delivery logs between the direct trigger and the Event Router path. Verify 100% event delivery parity over a 7-day observation window.
- Cutover phase: Disable direct triggers and route all events through the Event Router. Monitor DLQ and health dashboard for anomalies during the first 48 hours.
SQLite DLQ Schema
The Dead Letter Queue uses a single SQLite table with the following structure: event ID (UUID), event category, event type, full event payload (JSON), target consumer, failure reason, retry count, first failure timestamp, last retry timestamp, status (pending/retrying/exhausted/replayed), and expiry timestamp. Indexes on category, status, and first failure timestamp enable efficient querying for the health dashboard and replay operations.
Performance Considerations
The Event Router's critical path is event validation (taxonomy check) and rule evaluation (routing decision). Both operations are designed for constant-time performance: taxonomy validation is a hash lookup, and routing rules are pre-compiled into a trie structure on load. At the target throughput of 100 events/second, each event must complete routing in under 10ms to maintain the p99 latency target of 50ms. The primary bottleneck is n8n webhook delivery, which is why fire-and-forget semantics are essential -- the router does not wait for n8n's HTTP response.
Monitoring the Monitor
The health dashboard itself is a consumer of events. If the dashboard fails, it will not receive its own failure events. To address this, the router includes a heartbeat mechanism: a synthetic heartbeat event is emitted every 60 seconds. If the dashboard does not receive a heartbeat within 120 seconds, a file-based alert is written to a monitoring directory. This provides a second channel for detecting event system failures independent of the event system itself.
Security Considerations
Event payloads may contain sensitive data (file paths, agent outputs, error messages with stack traces). The routing rules support a "scrub" directive that strips specified fields from event payloads before delivery to non-privileged consumers. Security category events are automatically restricted to consumers with security clearance in the routing rules. The DLQ stores full payloads (for replay fidelity), so access to the SQLite database is restricted to the same permission level as the governance audit trail.