Process Knowledge Base.
Structured business process knowledge store that provides agents with decision rules, SOPs, domain constraints, and edge-case catalogs at decision points -- bridging the gap between episodic memory and actionable process intelligence.
1Problem Statement
The system currently manages two forms of knowledge effectively: episodic memory (stored in Qdrant as vectors -- past conversations, decisions, outcomes) and development workflows (encoded as skills with step-by-step procedures). However, there is a critical gap between these two layers: structured business process knowledge.
Business process knowledge encompasses the decision rules, standard operating procedures, domain constraints, and edge-case catalogs that govern how work should be done in specific contexts. This is the knowledge that a senior employee carries in their head -- the "when you see X, always do Y" rules, the "this process has 7 steps and you must not skip step 4" procedures, and the "watch out for this edge case that breaks the standard approach" warnings.
Without this structured layer, agents make decisions based on general capabilities and episodic recall. This leads to three systemic problems:
- Inconsistent decision-making: When two agents face the same decision point on different days, they may make different choices because there is no authoritative rule to consult. Episodic memory provides "what happened last time" but not "what should happen." The distinction matters -- past decisions may have been suboptimal, and without a rule, the agent cannot distinguish between a good precedent and a bad one.
- Implicit domain constraints: Every domain has constraints that are not captured in code or configuration. Insurance claim processing has regulatory requirements about notification timelines. Security remediation has severity-dependent SLA obligations. Infrastructure changes have change window restrictions. These constraints exist in documentation and human knowledge but are invisible to agents at the point where decisions are made.
- Repeated edge-case discovery: When an agent encounters an edge case for the first time, it may handle it correctly after exploration. But this knowledge is stored as episodic memory -- a specific instance, not a generalized rule. The next time a different agent encounters the same edge case pattern, it must rediscover the solution. Edge-case catalogs transform one-time discoveries into reusable knowledge.
The Process Knowledge Base fills this gap by providing a structured, queryable, version-controlled repository of business process knowledge that agents can consult at decision points. It transforms implicit organizational knowledge into explicit, machine-readable rules that produce consistent, constraint-aware, edge-case-informed decisions.
Knowledge Hierarchy
The system's knowledge architecture has three layers. The bottom layer is raw data: files, code, configurations. The middle layer is episodic memory: past interactions, decisions, and their outcomes stored as vectors in Qdrant. The top layer -- currently missing -- is process knowledge: the distilled rules, procedures, and constraints that should govern agent behavior. The Process Knowledge Base implements this top layer, completing the knowledge hierarchy.
2Architecture
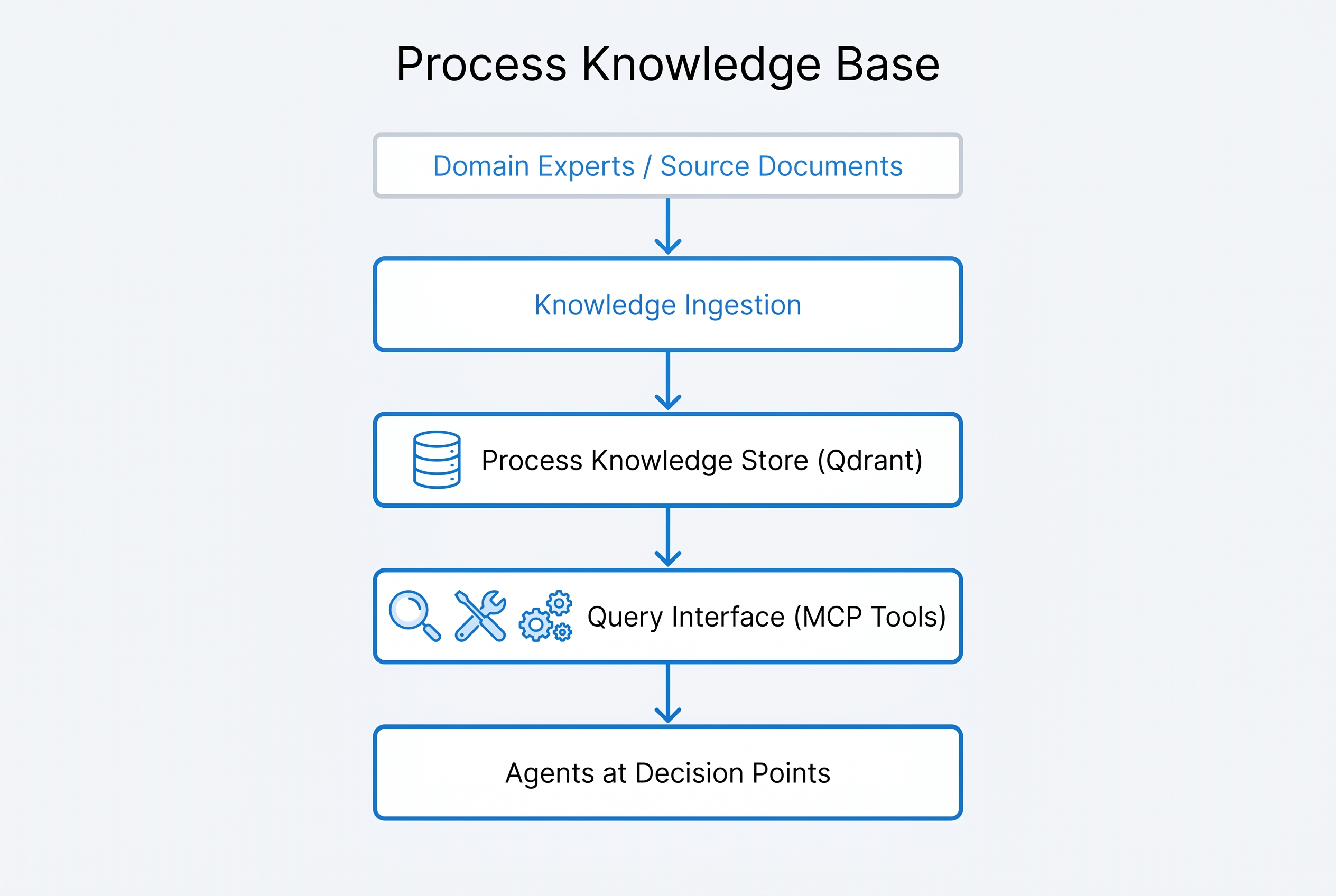
The Process Knowledge Base follows a four-stage pipeline: Knowledge Ingestion receives raw knowledge from multiple sources, the Process Knowledge Store persists structured knowledge in Qdrant with a dedicated collection, the Query Interface provides three MCP tools for agent access, and the output reaches Agents at Decision Points where process knowledge informs real-time choices.
Knowledge Types
The system defines four distinct knowledge types, each with a specific structure and query pattern:
Domain Packages
Process knowledge is organized into domain packages -- self-contained collections of rules, trees, SOPs, and catalogs for a specific operational domain:
Core Components
Knowledge Ingestion Pipeline
Four ingestion channels: (1) Manual entry via YAML authoring, (2) Document extraction from existing documentation, (3) Trajectory mining from successful memory trajectories, (4) Session extraction from conversation patterns. Each channel produces structured YAML that enters the human verification gate before persistence.
Process Knowledge Store
Dedicated Qdrant collection (process_knowledge) with vectors generated from knowledge content. Metadata includes: knowledge type, domain package, version, provenance, verification status, and usage count. Supports semantic search (find relevant rules for a situation) and exact lookup (retrieve a specific SOP by ID).
Query Interface (MCP Tools)
Three MCP tools provide agent access: process_query (semantic search for relevant knowledge), process_lookup (exact retrieval by ID or path), and process_validate (check a proposed action against applicable rules). Tools return structured responses with the knowledge item, its provenance, and confidence score.
Versioning and Provenance
Every knowledge item carries full provenance: original source (manual, document, trajectory, session), author, creation date, last modification date, version number, and verification status. Version history is maintained for audit and rollback. Provenance is returned with every query result so agents can assess knowledge reliability.
Human Verification Gate
All knowledge entering the store must pass human verification. Manually authored knowledge is verified at creation time. Automatically extracted knowledge (from trajectories, sessions, documents) enters a verification queue. Unverified knowledge is queryable but flagged as "unverified" in results, ensuring agents can distinguish between authoritative and provisional knowledge.
Knowledge Structure (YAML)
All knowledge items are authored and stored as YAML with a standardized structure. Each item includes metadata (ID, domain, type, version, provenance), the knowledge content itself (structured according to type -- rule conditions/actions, tree nodes/branches, SOP steps, catalog entries), applicability conditions (when this knowledge applies), and cross-references (related knowledge items, superseded items). The YAML source of truth enables version control, diffing, code review, and programmatic manipulation.
3Requirements
| ID | Requirement | Priority | Acceptance Criteria |
|---|---|---|---|
REQ-PK-001 |
Knowledge store must support exactly 4 knowledge types: rules, decision trees, SOPs, and edge case catalogs | HIGH | Each type has a defined YAML schema; items that do not conform to a type schema are rejected at ingestion |
REQ-PK-002 |
Knowledge must be organized into domain packages with defined boundaries | HIGH | Six initial domains (insurance, security, infrastructure, development, governance, operations); queries can be scoped to a specific domain |
REQ-PK-003 |
YAML must be the source of truth for all process knowledge | HIGH | Knowledge is authored in YAML, version controlled, and loaded into Qdrant from YAML; Qdrant is a query index, not the source of truth |
REQ-PK-004 |
Dedicated Qdrant collection for process knowledge, separate from episodic memory | HIGH | Collection process_knowledge exists independently; queries to process knowledge do not return episodic memories and vice versa |
REQ-PK-005 |
Three MCP tools for agent access: process_query, process_lookup, process_validate | HIGH | process_query returns semantically similar knowledge; process_lookup returns exact items by ID; process_validate checks actions against rules |
REQ-PK-006 |
Human verification gate required for all knowledge entering the store | HIGH | Manually authored knowledge verified at creation; extracted knowledge enters verification queue; unverified items flagged in query results |
REQ-PK-007 |
Every knowledge item must carry mandatory provenance metadata | HIGH | Provenance includes: source type, author, creation date, modification date, version, verification status; provenance returned with every query result |
REQ-PK-008 |
Knowledge ingestion pipeline must support 4 channels: manual, document extraction, trajectory mining, session extraction | MEDIUM | Manual channel operational at launch; extraction channels added incrementally; all channels produce standardized YAML output |
REQ-PK-009 |
Version history must be maintained for all knowledge items with rollback capability | MEDIUM | Each modification creates a new version; previous versions retrievable by version number; rollback restores a specific version as current |
REQ-PK-010 |
Knowledge items must support cross-references to related and superseded items | MEDIUM | Cross-references resolved at query time; superseded items return their replacement; related items returned as suggestions |
REQ-PK-011 |
process_validate tool must check proposed actions against all applicable rules and return violations | HIGH | Given an action description and domain context, returns: applicable rules, pass/fail per rule, violation details, suggested corrections |
REQ-PK-012 |
Usage tracking must record which knowledge items are queried, by which agents, and for which decisions | LOW | Usage data feeds into knowledge maintenance: high-usage items prioritized for verification; zero-usage items flagged for review |
REQ-PK-013 |
Knowledge query latency must be under 200ms for semantic search and under 50ms for exact lookup | MEDIUM | p95 latency measured across 1,000 queries; performance degrades gracefully with collection size up to 10,000 items |
REQ-PK-014 |
Edge case catalogs must link to the original discovery context (trajectory or session) | MEDIUM | Each edge case entry includes a reference to the source trajectory or session; reference is resolvable through the memory system |
4Design Decisions
-
YAML Source of Truth Over Database-Native Storage Process knowledge is authored and version-controlled as YAML files, with Qdrant serving as a query index rather than the primary store. This means knowledge can be reviewed in pull requests, diffed between versions, and audited through git history. If Qdrant is lost, knowledge can be rebuilt from YAML. The alternative (database-native authoring) would provide better real-time editing but lose the versioning, review, and auditability that YAML in git provides. For knowledge that governs critical decisions, auditability wins over convenience.
-
4 Knowledge Types Over Freeform Knowledge Restricting knowledge to exactly four types (rules, decision trees, SOPs, edge case catalogs) forces structure that enables machine consumption. A freeform knowledge store would accept any format but would require agents to interpret unstructured content at query time -- introducing variability and reducing reliability. The four types cover the known patterns of process knowledge; if a genuine fifth type emerges, the schema can be extended, but the barrier to extension is intentional.
-
Dedicated Qdrant Collection Over Shared Memory Collection Process knowledge uses its own Qdrant collection (
process_knowledge) rather than sharing the episodic memory collection. This prevents process knowledge queries from returning episodic memories (which look similar when vectorized) and allows independent tuning of embedding models, distance metrics, and indexing parameters. The cost is an additional collection to maintain, but the semantic separation between "what happened" (episodic) and "what should happen" (process) justifies the operational overhead. -
Human Verification Gate Over Automatic Acceptance All knowledge entering the store must pass human verification. This is especially critical for automatically extracted knowledge (from trajectories and sessions), which may contain errors, biases, or context-specific decisions that should not be generalized into rules. The verification gate adds latency to knowledge ingestion but ensures that the knowledge base remains authoritative. Unverified knowledge is accessible but flagged, providing a middle ground between blocking on verification and accepting everything.
-
MCP Tools Over Direct Qdrant Queries Agent access is mediated through three MCP tools rather than direct Qdrant API access. This provides a stable interface that can evolve independently of the storage layer, enables request logging for usage tracking, allows the query layer to enrich results with provenance and cross-references, and prevents agents from issuing arbitrary queries against the knowledge store. Direct Qdrant access would be faster but would couple agents to the storage implementation and bypass the enrichment layer.
-
Mandatory Provenance Over Optional Metadata Every knowledge item must carry full provenance (source, author, dates, version, verification status). This is not optional metadata -- it is a required field enforced at ingestion. Agents need provenance to assess knowledge reliability: a verified rule from an authoritative source carries more weight than an unverified extraction from a single session. Making provenance mandatory ensures agents always have the context to make informed trust decisions about the knowledge they receive.
5Integration Points
| System | PRD | Integration Type | Description |
|---|---|---|---|
| Memory System | PRD 4 | Bidirectional | Process Knowledge Base uses the same Qdrant infrastructure as the memory system but with a dedicated collection. Trajectory mining extracts candidate knowledge from successful memory trajectories. Edge case catalogs link back to original discovery contexts stored in episodic memory. |
| Governance Framework | PRD 5 | Knowledge Consumer | Governance agents query the process knowledge base for compliance rules, approval requirements, and jurisdiction-specific constraints. The process_validate tool is used by governance gates to check proposed actions against domain rules before approval. |
| Conductor Orchestrator | PRD 2 | Decision Support | The conductor queries process knowledge during tier classification and agent routing to apply domain-specific rules. SOPs inform phase sequencing. Decision trees guide complex routing decisions that depend on project context. |
| Obsidian Vault | External | Source Material | Existing documentation in the Obsidian vault serves as source material for the document extraction ingestion channel. SOPs, procedures, and domain notes in the vault can be transformed into structured YAML knowledge items. |
| Markdown-for-Agents | PRD 7 | Format Alignment | Knowledge items follow the markdown-for-agents formatting standards when presented to agents, ensuring consistent rendering and parsing. YAML frontmatter on knowledge items aligns with the agent-readable markdown specification. |
| Context Guard | PRD 3 | Budget Coordinator | Process knowledge query results consume context budget. Context Guard tracks knowledge retrieval size and ensures that large SOPs or decision trees do not exceed context limits. Knowledge items include a size estimate for budget planning. |
| Event-Driven Automation | PRD 13 | Event Consumer | Knowledge ingestion events (new item, verification status change, version update) are emitted to the event system. Downstream workflows can react to knowledge changes -- for example, notifying domain experts when new unverified knowledge enters their domain package. |
6Prompt to Build It
The following prompt can be used to instruct Claude Code to build the Process Knowledge Base. It encapsulates the full specification from this PRD.
Build a Process Knowledge Base that provides structured business process knowledge to agents at decision points. The system bridges the gap between episodic memory (what happened) and process intelligence (what should happen).
Core components to implement:
1. KNOWLEDGE STRUCTURE — 4 knowledge types with YAML schemas:
- Rules: IF-THEN decision rules with conditions, actions, exceptions, and applicability scope
- Decision Trees: Multi-step branching logic with condition nodes, action branches, and terminal states
- SOPs: Ordered step sequences with prerequisites, actions, validation criteria, and rollback procedures per step
- Edge Case Catalogs: Collections of known exceptions with trigger patterns, why standard approach fails, and correct alternatives
Each item includes mandatory metadata: ID, domain, type, version, provenance (source, author, dates, verification status), applicability conditions, and cross-references.
2. DOMAIN PACKAGES — 6 initial domains:
- Insurance: claim rules, regulatory timelines, coverage trees, jurisdiction constraints, multi-policy edge cases
- Security: vulnerability triage, severity SLAs, incident response SOPs, false positive edge cases
- Infrastructure: change windows, deployment SOPs, rollback procedures, cascading failure edge cases
- Development: code review rules, branching SOPs, dependency update trees, breaking change edge cases
- Governance: approval gate rules, compliance SOPs, data classification trees, cross-jurisdiction edge cases
- Operations: monitoring alert rules, escalation SOPs, capacity trees, coverage gap edge cases
3. KNOWLEDGE INGESTION PIPELINE — 4 channels:
- Manual: Direct YAML authoring by domain experts
- Document extraction: Parse existing documentation into structured YAML
- Trajectory mining: Extract candidate rules/SOPs from successful memory trajectories
- Session extraction: Identify process patterns from conversation history
All channels produce standardized YAML. ALL ingested knowledge enters a human verification queue. Unverified knowledge is queryable but flagged.
4. QUERY INTERFACE — 3 MCP tools:
- process_query: Semantic search against the process_knowledge Qdrant collection. Parameters: query text, domain filter (optional), knowledge type filter (optional), limit. Returns: matching items with content, provenance, confidence score.
- process_lookup: Exact retrieval by ID or path. Parameters: item ID or domain/path. Returns: full knowledge item with all metadata and version history.
- process_validate: Check a proposed action against applicable rules. Parameters: action description, domain context. Returns: applicable rules, pass/fail per rule, violation details, suggested corrections.
5. VERSIONING AND PROVENANCE:
- YAML files are the source of truth, version-controlled in git
- Qdrant collection (process_knowledge) is a query index rebuilt from YAML
- Each modification creates a new version; previous versions retrievable
- Provenance is mandatory: source type, author, creation date, modification date, version number, verification status
- Cross-references: related items, superseded items (superseded items return their replacement)
- Usage tracking: which items queried, by which agents, for which decisions
Design constraints:
- YAML source of truth — Qdrant is a query index, not the primary store
- Exactly 4 knowledge types — no freeform knowledge
- Dedicated Qdrant collection — separate from episodic memory
- Human verification gate — mandatory for all ingested knowledge
- MCP tools over direct Qdrant access — stable interface, usage logging, result enrichment
- Mandatory provenance — every item, every query result
- Query latency: under 200ms for semantic search, under 50ms for exact lookup
- Edge case catalogs link to original discovery context in episodic memory
File locations:
- Knowledge YAML: ~/.claude/knowledge/{domain}/{type}/*.yaml
- Schemas: ~/.claude/knowledge/schemas/
- Ingestion pipeline: ~/.claude/knowledge/ingestion/
- MCP tools: ~/.claude/knowledge/tools/
- Verification queue: ~/.claude/knowledge/verification/
Integration points:
- Memory system (shared Qdrant infrastructure, trajectory mining, edge case links)
- Governance framework (compliance rules, approval requirements, jurisdiction constraints)
- Conductor orchestrator (domain-specific routing rules, phase sequencing SOPs)
- Obsidian vault (source material for document extraction)
- Context Guard (knowledge retrieval budget coordination)
- Event-driven automation (emit knowledge change events)
7Implementation Notes
Phased Delivery
The Process Knowledge Base should be delivered in three phases:
- Phase 1 — Foundation (Week 1-2): Define YAML schemas for all 4 knowledge types. Implement the
process_knowledgeQdrant collection with vector embedding pipeline. Build theprocess_lookupMCP tool for exact retrieval. Seed the security and development domain packages with 10-15 knowledge items each from existing documentation. This phase validates the knowledge structure and provides immediate value through lookup queries. - Phase 2 — Query Intelligence (Week 3-4): Implement
process_query(semantic search) andprocess_validate(action validation) MCP tools. Add the human verification gate and provenance tracking. Build the manual ingestion channel with YAML validation. Extend domain packages to all 6 domains. This phase enables agents to find relevant knowledge and validate proposed actions. - Phase 3 — Automated Extraction (Week 5-6): Build the trajectory mining and session extraction ingestion channels. Add version history and cross-reference resolution. Implement usage tracking. Integrate with the event-driven automation system for knowledge change events. This phase adds the automated knowledge discovery that scales the system beyond manual authoring.
YAML Schema Design
Each knowledge type has a defined YAML schema that enforces structure while allowing domain-specific flexibility:
- Rules schema:
id,domain,conditions(array of IF clauses),action(THEN clause),exceptions(array of UNLESS clauses),applicability(when this rule applies),provenance,cross_refs. - Decision Tree schema:
id,domain,root_node(entry point),nodes(array of condition/action nodes),edges(connections between nodes with conditions),terminal_states(leaf outcomes),provenance,cross_refs. - SOP schema:
id,domain,steps(ordered array), each step:name,prerequisites,action,validation,rollback,notes. Plusprovenance,cross_refs. - Edge Case schema:
id,domain,trigger_pattern(what signals this edge case),standard_approach(what would normally be done),why_fails(why the standard approach does not work here),correct_alternative,discovery_context(link to source trajectory/session),provenance,cross_refs.
Qdrant Collection Configuration
The process_knowledge collection uses the same embedding model as episodic memory for consistency but with different indexing parameters optimized for the knowledge retrieval pattern. Knowledge items are typically shorter and more structured than episodic memories, so a smaller vector size may be appropriate. The collection supports filtered search by domain and knowledge type, enabling scoped queries that reduce result noise.
Verification Queue Workflow
Automatically extracted knowledge enters the verification queue as a YAML file in the verification/ directory with metadata indicating its extraction source and confidence score. A periodic review process (manual or via n8n workflow notification) presents pending items to domain experts for approval, rejection, or modification. Approved items move to the domain package directory and are indexed in Qdrant. Rejected items are archived with the rejection reason. Modified items are updated in-place before approval.
Performance Optimization
Semantic search (process_query) must return results within 200ms. The primary optimization is pre-filtering by domain before vector search, which reduces the search space by approximately 6x (one domain out of six). For the process_validate tool, rule evaluation is structured as a parallel scan of all rules in the applicable domain, with short-circuit evaluation for rules that cannot apply based on the action's context. At the expected collection size (100-500 items per domain), these optimizations maintain sub-200ms latency with margin.
Knowledge Lifecycle
Knowledge items follow a defined lifecycle: Draft (authored but not verified) -> Verified (human-approved, active) -> Superseded (replaced by a newer version, returns redirect) -> Archived (no longer applicable, hidden from default queries). Usage tracking identifies stale knowledge (verified items with zero queries over 90 days), which is flagged for review. The lifecycle ensures the knowledge base remains current and relevant rather than accumulating outdated rules.
Security Considerations
Some knowledge items may contain sensitive information (security remediation procedures, compliance requirements with regulatory references, infrastructure topology details). Domain packages support an access level attribute (public, internal, restricted) that the MCP tools enforce at query time. Restricted knowledge is only returned to agents operating within a conductor workflow that has the appropriate security clearance, as determined by the governance framework.