Self-Healing Workflows.
Automated recovery engine for multi-agent workflow failures. Classifies failure modes, selects recovery strategies from YAML playbooks, and manages granular checkpoints with SHA-256 integrity validation.
1Problem Statement
Multi-agent orchestration workflows are inherently fragile. APIs time out, language models hallucinate, containers crash, rate limits trigger at inopportune moments, and external services return unexpected responses. In the current system, every one of these failure modes requires manual triage by a human operator -- discovering the failure, diagnosing the root cause, deciding on a recovery strategy, and re-executing the affected workflow steps.
This manual recovery pattern creates three compounding problems:
- Latency amplification: A 30-second API timeout becomes a 30-minute recovery cycle when a human must context-switch, read logs, understand the workflow state, and decide how to proceed. Overnight failures discovered the next morning lose 8+ hours of potential progress.
- Knowledge loss: The operator's recovery decisions are not captured in any structured format. The same failure pattern may require the same manual intervention repeatedly because no institutional memory of "what worked last time" exists.
- Cascading damage: Without granular checkpoints, a failure in step 7 of a 12-step workflow often requires re-executing steps 1-6 because intermediate state was not preserved. This wastes compute, burns context budget, and risks introducing drift between the original execution and the recovery execution.
The gap is a structured, automated recovery system that can classify failures into known categories, apply the appropriate recovery strategy from a pre-defined playbook, and manage workflow state at a granularity that allows partial rollback without full re-execution. The system must also know when to stop trying and escalate to a human, preserving the principle that automated recovery should never make a bad situation worse.
Current Failure Landscape
Analysis of orchestration logs over the past 90 days reveals a consistent distribution of failure types. Transient failures (network timeouts, rate limits, temporary service unavailability) account for roughly 45% of all workflow interruptions and are almost always recoverable with a simple retry and backoff strategy. Model-related failures (hallucinated outputs, context overflow, malformed structured output) represent approximately 25% and typically require a model downgrade or prompt restructuring. The remaining 30% spans permission errors, data corruption, infrastructure failures, logic errors, and external service outages -- each demanding a distinct recovery approach.
Despite this predictable distribution, the current system treats every failure identically: it stops and waits for a human. A self-healing system that handles even the 45% transient failure category autonomously would eliminate nearly half of all manual recovery interventions.
2Architecture
The Self-Healing Recovery Engine sits as an intermediary layer between the conductor orchestrator and the dispatched agents. It intercepts failure signals, classifies them, selects a recovery strategy, and manages the re-execution loop. The architecture is designed around five core components that operate in a coordinated pipeline.
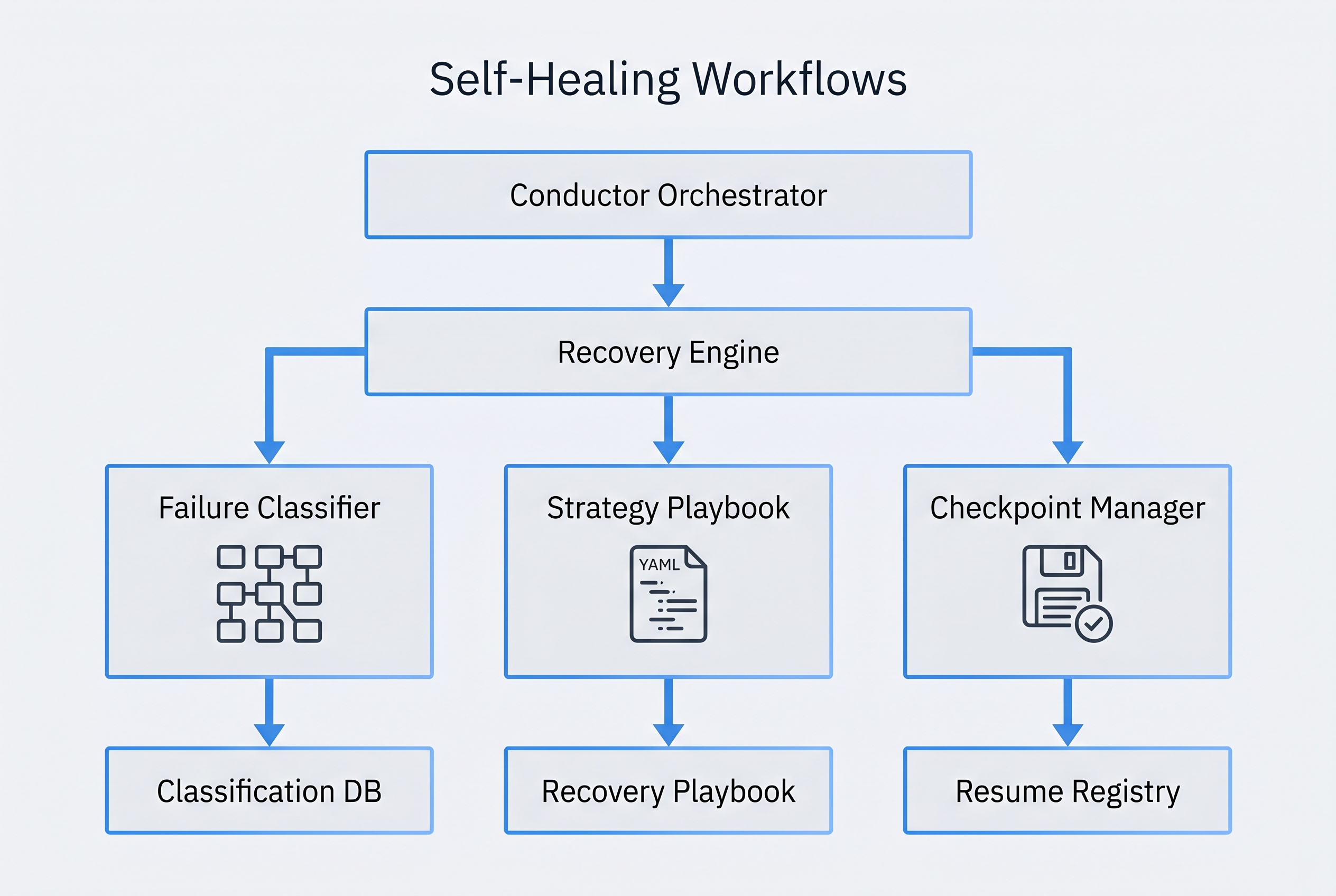
System Flow
When the conductor dispatches an agent via the Task tool, the Recovery Engine wraps the dispatch with checkpoint management. Before the agent executes, a pre-execution checkpoint captures the current workflow state, including all file artifacts, state JSON, and relevant context. The agent then executes normally.
If the agent returns a failure signal (non-zero exit, error in output, validation failure from the Gemini validator, or timeout), the failure enters the classification pipeline. The Failure Classifier analyzes error signatures against known patterns and assigns one of seven failure categories. The category maps to a specific recovery strategy in the Strategy Playbook. The Checkpoint Manager provides the rollback target. The recovery executes, and the entire cycle is logged to the Recovery Audit Trail.
Core Components
Failure Classifier
Pattern-matching engine that analyzes error output, exit codes, and execution context to categorize failures into one of seven defined categories. Uses regex-based signature matching rather than ML to ensure deterministic, auditable classification. Each category has a confidence threshold; below-threshold classifications trigger escalation to human review.
Strategy Playbook
YAML-defined recovery strategies mapped to failure categories. Each strategy specifies: the recovery action (retry, fallback, downgrade, degrade, escalate), maximum attempts, backoff configuration, pre-conditions for applicability, and post-recovery validation requirements. Strategies are composable -- a category can define a chain of strategies to attempt in sequence.
Checkpoint Manager
Granular state snapshot system that captures workflow state before each agent dispatch. Checkpoints include file hashes (SHA-256), conductor-state.json snapshots, BRD-tracker state, and git commit references. Supports partial rollback -- restoring state to any checkpoint without affecting artifacts created by other workflow branches.
Recovery Audit Trail
Structured event log integrated with the governance audit bus. Records every failure detection, classification decision, recovery strategy selection, execution attempt, and outcome. Provides the data substrate for failure pattern analysis, playbook optimization, and compliance reporting.
Health Monitor
Background infrastructure health check system that proactively detects degraded conditions before they cause agent failures. Monitors API endpoint availability, model response latency, container health, disk space, and external service status. Health signals influence the Strategy Playbook's pre-condition evaluation -- if the monitor reports a known outage, the playbook can skip retry strategies and go directly to fallback.
Failure Categories
The Failure Classifier operates with seven distinct categories, each with defined signature patterns and default recovery strategies:
| Category | Signature Patterns | Default Strategy | Max Retries |
|---|---|---|---|
| Transient | HTTP 429/503/504, ECONNRESET, ETIMEDOUT, "rate limit" | Exponential backoff retry | 3 |
| Model | Context overflow, malformed JSON output, hallucinated tool calls, safety refusal | Model downgrade + prompt trim | 2 |
| Data | Schema validation failure, missing required fields, type mismatch, corrupt JSON | Checkpoint rollback + re-execute | 2 |
| Permission | EACCES, HTTP 401/403, "permission denied", git auth failure | Escalate to operator | 0 |
| Logic | Assertion failures, invariant violations, infinite loops detected, conflicting state | Checkpoint rollback + alternate agent | 1 |
| Infrastructure | OOM kill, disk full, container crash, process exit without error | Resource cleanup + retry | 2 |
| External | Third-party API errors, webhook failures, DNS resolution failures | Graceful degradation | 2 |
Recovery Strategy Chain
Strategies execute in a defined order when the primary strategy fails. For example, a transient failure first attempts exponential backoff retry (up to 3 attempts). If retries are exhausted, the strategy chain escalates to fallback (use cached/stale data if available), then to degradation (skip the failing step and mark as degraded), and finally to human escalation. Each transition in the chain is logged to the audit trail with the reason for escalation.
Checkpoint Integrity
Every checkpoint includes a SHA-256 manifest of all captured artifacts. Before restoring a checkpoint, the manager verifies the manifest hash against the stored artifacts. If any artifact has been tampered with or corrupted, the restore is aborted and the failure escalates. This prevents recovery from introducing corrupted state into the workflow.
3Requirements
| ID | Requirement | Priority | Acceptance Criteria |
|---|---|---|---|
REQ-SH-001 |
Failure Classifier must categorize failures into exactly 7 categories with deterministic pattern matching | HIGH | Given any agent failure output, the classifier assigns exactly one category with a confidence score; classification is reproducible for identical inputs |
REQ-SH-002 |
Recovery Strategy Playbook must be defined in YAML with composable strategy chains per failure category | HIGH | Each failure category maps to an ordered list of strategies; strategies specify action, max attempts, backoff, and validation |
REQ-SH-003 |
Checkpoint Manager must capture granular state snapshots before every agent dispatch | HIGH | Checkpoints include file hashes, state JSON, BRD tracker, and git refs; any checkpoint can be independently restored |
REQ-SH-004 |
All checkpoints must include SHA-256 manifests for integrity validation on restore | HIGH | Restore aborts if any artifact hash mismatch is detected; abort event logged to audit trail |
REQ-SH-005 |
Recovery Engine must support partial rollback without affecting unrelated workflow branches | HIGH | Rolling back step 7 does not modify artifacts created by steps in parallel branches |
REQ-SH-006 |
Every recovery action must be logged to the governance audit bus with structured event data | HIGH | Audit events include: failure category, confidence, strategy selected, attempt number, outcome, duration |
REQ-SH-007 |
Maximum 2 automated retry attempts before escalation to human operator | HIGH | After 2 failed recovery attempts for non-transient failures, the system halts and presents diagnostics to the operator |
REQ-SH-008 |
Health Monitor must proactively check infrastructure before agent dispatch | MEDIUM | Pre-dispatch health check covers API endpoints, model availability, disk space; degraded health modifies strategy selection |
REQ-SH-009 |
Transient failures must use exponential backoff with configurable base delay and maximum delay | MEDIUM | Default base delay: 2 seconds, max delay: 60 seconds, jitter: +/- 20%; all configurable via YAML |
REQ-SH-010 |
Model failures must support automatic model downgrade with prompt trimming | MEDIUM | Context overflow triggers model switch from primary to fallback model with automatic context reduction |
REQ-SH-011 |
Recovery strategies must be composable into ordered chains with fallthrough semantics | MEDIUM | A strategy chain of [retry, fallback, degrade, escalate] executes in order until one succeeds or all fail |
REQ-SH-012 |
Permission failures must escalate immediately without automated retry | HIGH | Permission errors bypass the retry loop entirely and present the operator with the specific permission required |
REQ-SH-013 |
Recovery Audit Trail must support querying by time range, failure category, workflow ID, and outcome | MEDIUM | Audit query API returns structured results with pagination; supports export to JSON |
REQ-SH-014 |
The system must fail open -- recovery engine unavailability must not block normal workflow execution | HIGH | If the recovery engine itself fails, workflows continue without self-healing capability; degradation is logged but not blocking |
4Design Decisions
-
Fail Open, Not Fail Closed The recovery engine itself is not a blocking dependency. If the engine is unavailable, workflows execute normally without self-healing capability. This prevents the recovery system from becoming a single point of failure. The alternative (fail closed) would mean any bug in the recovery engine halts all workflow execution, which violates the principle that recovery should never make things worse.
-
YAML Strategy Playbook Over Code-Defined Strategies Recovery strategies are defined in YAML rather than hardcoded in the recovery engine. This allows operators to customize strategies, add new failure patterns, and adjust retry counts without modifying engine code. YAML playbooks are also versionable, diffable, and auditable -- critical properties for a governance-integrated system. The tradeoff is slightly reduced performance versus a compiled strategy engine, but recovery speed is not latency-sensitive.
-
Granular Checkpoints Over Full-State Snapshots Checkpoints capture only the artifacts and state relevant to the current agent dispatch, not the entire workflow state. This reduces checkpoint storage by approximately 80% and enables partial rollback of individual workflow steps without affecting unrelated branches. The cost is increased complexity in the checkpoint-restore logic, which must track artifact ownership across workflow branches.
-
Pattern Matching Over Machine Learning for Classification The Failure Classifier uses regex-based pattern matching rather than a trained ML model. This ensures deterministic, reproducible classification -- the same error output always produces the same category. ML-based classification would potentially achieve higher accuracy on novel failure modes but at the cost of non-determinism, training data requirements, and reduced auditability. The pattern library is extensible; new patterns can be added to the YAML configuration as novel failure modes are discovered.
-
Explicit Fallback Mapping Over Automatic Discovery Each agent in the capability matrix has an explicitly defined fallback agent (or "no fallback" designation). The system does not attempt to automatically discover alternative agents based on capability overlap. Explicit mapping prevents the recovery engine from dispatching an inappropriate agent during a stress scenario. The mapping is maintained in the capabilities YAML alongside the primary routing configuration.
-
Advisory Health Monitor Over Blocking Health Gates The Health Monitor provides signals that influence strategy selection but does not block agent dispatch. A degraded health signal might cause the playbook to skip retry strategies (avoiding wasted retries against a known-down service) but will not prevent the agent from executing. Blocking health gates were considered but rejected because they introduce false-negative risk -- a health check might report an endpoint as down when it is actually recovering.
-
Reuse Existing Governance Audit Bus Over Custom Logging Recovery events are emitted to the existing governance audit bus rather than a separate recovery-specific log. This ensures recovery data is queryable through the same interfaces used for governance compliance, security events, and operational telemetry. The audit bus already supports structured events, time-range queries, and JSON export -- capabilities the recovery system needs without re-implementation.
5Integration Points
| System | PRD | Integration Type | Description |
|---|---|---|---|
| Conductor Orchestrator | PRD 2 | Bidirectional | Recovery Engine wraps conductor's agent dispatch calls. Receives failure signals from conductor, returns recovery outcomes. Modifies workflow state during rollback operations. |
| Governance Framework | PRD 5 | Event Producer | Emits structured recovery events to the governance audit bus. Events include failure classification, strategy selection, recovery outcomes, and escalation triggers. Governance can query recovery history for compliance reporting. |
| Agent Economics | PRD 10 | Cost Consumer | Recovery retries consume compute budget tracked by Agent Economics. Model downgrades affect cost calculations. Recovery Engine queries remaining budget before executing expensive retry strategies. |
| Runtime Security | PRD 11 | Constraint Provider | Runtime Security enforces boundaries on recovery actions. The Recovery Engine cannot escalate permissions, bypass security gates, or execute recovery strategies that violate security policies. |
| Context Guard | PRD 3 | Resource Coordinator | Context Guard manages the 60% context budget. Recovery retries must respect context limits. Model downgrade strategies coordinate with Context Guard to determine appropriate context trimming. |
| Memory System | PRD 4 | Pattern Store | Successful recovery patterns are stored as trajectories in the memory system. Future failure classifications can query memory for similar past recoveries, improving strategy selection over time. |
| n8n Automation | External | Webhook Trigger | Recovery events trigger n8n workflows for notifications (Slack alerts on escalation), dashboarding (recovery metrics), and extended automation (infrastructure remediation scripts). |
6Prompt to Build It
The following prompt can be used to instruct Claude Code to build the Self-Healing Workflow Recovery Engine. It encapsulates the full specification from this PRD.
Build a self-healing workflow recovery engine for the conductor orchestration system. The engine sits between the conductor orchestrator and dispatched agents, intercepting failures and applying automated recovery. Core components to implement: 1. FAILURE CLASSIFIER — Pattern-matching engine with 7 failure categories: - Transient (HTTP 429/503/504, ECONNRESET, ETIMEDOUT, rate limits) - Model (context overflow, malformed JSON, hallucinated tool calls, safety refusals) - Data (schema validation, missing fields, type mismatch, corrupt JSON) - Permission (EACCES, HTTP 401/403, auth failures) - Logic (assertion failures, invariant violations, infinite loops, conflicting state) - Infrastructure (OOM, disk full, container crash, silent process exit) - External (third-party API errors, webhook failures, DNS failures) Use regex-based signature matching — no ML. Each classification must include a confidence score. Below-threshold confidence triggers human escalation. 2. STRATEGY PLAYBOOK — YAML-defined recovery strategies: - Each failure category maps to an ordered chain of strategies - Strategies: retry (exponential backoff), fallback (cached/stale data), downgrade (model switch), degrade (skip + mark degraded), escalate (human intervention) - Configurable: max attempts, base delay, max delay, jitter, pre-conditions, post-recovery validation - Default backoff: 2s base, 60s max, +/-20% jitter - Max 2 retries for non-transient failures, max 3 for transient 3. CHECKPOINT MANAGER — Granular state snapshots: - Capture before every agent dispatch: file hashes (SHA-256), conductor-state.json, BRD-tracker.json, git commit ref - SHA-256 manifest for integrity validation on restore - Partial rollback — restore individual steps without affecting parallel branches - Abort restore if any hash mismatch detected 4. RECOVERY AUDIT TRAIL — Governance-integrated logging: - Emit structured events to the governance audit bus - Event data: failure category, confidence, strategy selected, attempt number, outcome, duration, workflow ID - Support queries by time range, failure category, workflow ID, outcome 5. HEALTH MONITOR — Advisory infrastructure checks: - Pre-dispatch checks: API endpoints, model availability, disk space, container health - Health signals influence strategy selection (skip retries for known outages) - Advisory only — never blocks dispatch - Background check interval: configurable Design constraints: - Fail open: recovery engine unavailability must not block workflows - Permission failures escalate immediately — no automated retry - Pattern matching is deterministic and reproducible - Explicit fallback agent mapping in capabilities YAML — no automatic discovery - All recovery actions respect the 60% context budget and compute budget limits - Recovery events integrate with the existing governance audit bus - Successful recovery patterns stored as memory trajectories for future reference File locations: - Strategy playbook: ~/.claude/recovery/strategy-playbook.yaml - Failure patterns: ~/.claude/recovery/failure-patterns.yaml - Checkpoint storage: .conductor/checkpoints/ (per-project) - Recovery state: conductor-state.json (recovery_history array) Integration points: - Conductor orchestrator (wrap dispatch, receive failures, modify state) - Governance audit bus (emit recovery events) - Agent Economics (query budget before expensive retries) - Runtime Security (respect security constraints on recovery actions) - Context Guard (coordinate context trimming on model downgrades) - Memory system (store successful recovery trajectories) - n8n (webhook triggers for notifications and extended automation)
7Implementation Notes
Phased Delivery
The self-healing engine should be delivered in three phases to manage complexity and risk:
- Phase 1 — Transient Recovery (Week 1-2): Implement the Failure Classifier with transient failure patterns only, exponential backoff retry strategy, and basic checkpoint capture. This phase alone addresses ~45% of manual recovery interventions and validates the architecture.
- Phase 2 — Full Classification (Week 3-4): Extend the classifier to all 7 categories, implement the full strategy playbook with composable chains, and add SHA-256 checkpoint integrity. Integrate with the governance audit bus.
- Phase 3 — Intelligence Layer (Week 5-6): Add the Health Monitor, memory-backed pattern learning, n8n webhook integration, and recovery analytics dashboard. Implement partial rollback for parallel workflow branches.
Testing Strategy
Each failure category requires a dedicated test harness that can simulate the corresponding failure mode. For transient failures, a mock HTTP server that returns configurable error codes. For model failures, a mock model endpoint that returns malformed output. For infrastructure failures, containerized environments with resource limits that can be triggered. The test suite must verify:
- Classification accuracy: 100% of known patterns correctly categorized
- Strategy chain execution: each strategy in a chain is attempted in order
- Checkpoint integrity: tampered checkpoints are detected and restore is aborted
- Escalation timing: human escalation occurs within 2 retry attempts
- Fail-open behavior: workflow continues when recovery engine is disabled
- Audit completeness: every recovery action produces a structured audit event
Operational Considerations
Checkpoint storage will grow proportionally with workflow volume. A retention policy should prune checkpoints older than 7 days for completed workflows and 30 days for failed workflows. The recovery audit trail shares the governance audit bus's retention policy. The strategy playbook should be reviewed quarterly to incorporate new failure patterns discovered in production.
The Health Monitor's check interval should be tuned to balance early detection against unnecessary load. A 30-second interval is the recommended starting point, with adaptive adjustment based on failure frequency -- more frequent checks during periods of elevated failure rates.
Security Considerations
The recovery engine has elevated privileges -- it can modify workflow state, rollback file changes, and re-dispatch agents. These privileges must be constrained by Runtime Security (PRD 11) boundaries. Specifically: the engine cannot escalate permissions beyond what the original dispatch had, cannot bypass security gates during recovery, and cannot modify files outside the project workspace. All privilege usage is logged to the audit trail for post-hoc review.
Performance Budget
Checkpoint capture must complete in under 500ms to avoid meaningful latency on agent dispatch. SHA-256 hashing of typical workflow artifacts (10-50 files, 1-5MB total) completes well within this budget on modern hardware. The failure classifier's pattern matching operates in constant time relative to the number of patterns (currently ~50 patterns across 7 categories). Strategy selection is O(1) -- a direct map lookup from category to strategy chain.